
FROMThis chapter introduces you to the fundamentals of the 本章向您介绍SELECT statement, focusing for now on queries against a single table. SELECT语句的基本原理,目前主要关注针对单个表的查询。The chapter starts by describing logical query processing—namely, the series of logical phases involved in producing the correct result set of a particular 本章首先描述逻辑查询处理,即生成特定SELECT query. SELECT查询的正确结果集所涉及的一系列逻辑阶段。The chapter then covers other aspects of single-table queries, including predicates and operators, 然后,本章将介绍单表查询的其他方面,包括谓词和运算符、CASE expressions, NULLs, all-at-once operations, manipulating character data and date and time data, and querying metadata. CASE表达式、null、一次性操作、操作字符数据、日期和时间数据,以及查询元数据。Many of the code samples and exercises in this book use a sample database called 本书中的许多代码示例和练习都使用一个名为TSQLV4. TSQLV4的示例数据库。You can find the instructions for downloading and installing this sample database in the Appendix, “Getting started.”您可以在附录“入门”中找到下载和安装此示例数据库的说明。
SELECT statementSELECT语句的元素The purpose of a SELECT statement is to query tables, apply some logical manipulation, and return a result. SELECT语句的用途是查询表、应用一些逻辑操作并返回结果。In this section, I talk about the phases involved in logical query processing. 在本节中,我将讨论逻辑查询处理所涉及的阶段。I describe the logical order in which the different query clauses are processed and what happens in each phase.我描述了处理不同查询子句的逻辑顺序,以及每个阶段发生的事情。
Note that by “logical query processing,” I'm referring to the conceptual way in which standard SQL defines how a query should be processed and the final result achieved. 请注意,通过“逻辑查询处理”,我指的是标准SQL定义查询应如何处理和最终结果的概念性方式。Don't be alarmed if some logical processing phases that I describe here seem inefficient. 如果我在这里描述的一些逻辑处理阶段似乎效率低下,请不要惊慌。The database engine doesn't have to follow logical query processing to the letter; rather, it is free to physically process a query differently by rearranging processing phases, as long as the final result would be the same as that dictated by logical query processing. 数据库引擎不必完全遵循逻辑查询处理;相反,只要最终结果与逻辑查询处理的结果相同,就可以通过重新安排处理阶段,以不同的方式对查询进行物理处理。The database engine's query optimizer can—and in fact, often does—make many shortcuts in the physical processing of a query as a result of query optimization.作为查询优化的结果,数据库引擎的查询优化器可以而且实际上经常在查询的物理处理中创建许多快捷方式。
To describe logical query processing and the various 为了描述逻辑查询处理和各种SELECT query clauses, I use the query in Listing 2-1 as an example.SELECT查询子句,我以Listing 2-1中的查询为例。
LISTING 2-1 Sample query示例查询
USE TSQLV4;
SELECT empid, YEAR(orderdate) AS orderyear, COUNT(*) AS numorders
FROM Sales.Orders
WHERE custid = 71
GROUP BY empid, YEAR(orderdate)
HAVING COUNT(*) > 1
ORDER BY empid, orderyear;
This query filters orders that were placed by customer 71, groups those orders by employee and order year, and filters only groups of employees and years that have more than one order. 此查询筛选客户71下的订单,按员工和订单年份对这些订单进行分组,并仅过滤具有多个订单的员工组和年份。For the remaining groups, the query presents the employee ID, order year, and count of orders, sorted by the employee ID and order year. 对于其余的组,查询将显示员工ID、订单年份和订单数量,按员工ID和订单年份排序。For now, don't worry about understanding how this query does what it does; I'll explain the query clauses one at a time and gradually build this query.现在,不要担心理解这个查询是如何实现的;我将一次解释一个查询子句,并逐步构建这个查询。
The code starts with a 代码以一个USE statement that ensures that the database context of your session is the TSQLV4 sample database. USE语句开始,该语句确保会话的数据库上下文是TSQLV4范例数据库。If your session is already in the context of the database you need to query, the 如果会话已经在需要查询的数据库上下文中,则不需要USE statement is not required.USE语句。
Before I get into the details of each phase of the 在讨论SELECT statement, notice the order in which the query clauses are logically processed. SELECT语句每个阶段的细节之前,请注意逻辑处理查询子句的顺序。In most programming languages, the lines of code are processed in the order that they are written. 在大多数编程语言中,代码行是按照编写顺序进行处理的。In SQL, things are different. 在SQL中,情况有所不同。Even though the 即使SELECT clause appears first in the query, it is logically processed almost last. SELECT子句首先出现在查询中,但它在逻辑上几乎是最后一个被处理的。The clauses are logically processed in the following order:这些子句按以下顺序进行逻辑处理:
1. FROM
2. WHERE
3. GROUP BY
4. HAVING
5. SELECT
6. ORDER BY
So even though syntactically the sample query in Listing 2-1 starts with a 因此,尽管Listing 2-1中的示例查询在语法上以SELECT clause, logically its clauses are processed in the following order:SELECT子句开头,但从逻辑上讲,其子句的处理顺序如下:
FROM Sales.Orders
WHERE custid = 71
GROUP BY empid, YEAR(orderdate)
HAVING COUNT(*) > 1
SELECT empid, YEAR (orderdate) AS orderyear, COUNT(*) AS numorders
ORDER BY empid, orderyear
Or, to present it in a more readable manner, here's what the statement does:或者,为了更具可读性,以下是该语句的作用:
1. Queries the rows 查询from the Sales.Orders tableSales.Orders表中的行
2. Filters only orders 仅筛选客户ID等于71的订单where the customer ID is equal to 71
3. Groups the orders by employee ID and order year
4. Filters only groups (employee ID and order year) 仅筛选具有多个订单的组(员工ID和订单年)having more than one order
5. Selects (returns) for each group the employee ID, order year, and number of orders
6. Orders (sorts) the rows in the output by employee ID and order year
You cannot write the query in correct logical order. 无法按正确的逻辑顺序编写查询。You have to start with the 必须从SELECT clause, as shown in Listing 2-1. SELECT子句开始,如Listing 2-1所示。There's reason behind this discrepancy between the keyed-in order and the logical processing order of the clauses. 这些子句的输入顺序和逻辑处理顺序之间的差异是有原因的。The designers of SQL envisioned a declarative language with which you provide your request in an English-like manner. SQL的设计者设想了一种声明性语言,您可以用这种语言以类似英语的方式提供请求。Consider an instruction made by one human to another in English, such as, “Bring me the car keys from the top-left drawer in the kitchen.” 考虑一个人用英语做另一个人的指令,比如“把厨房钥匙从厨房左上抽屉拿来。”Notice that you start the instruction with the object and then indicate the location where the object resides. 请注意,指令从对象开始,然后指出对象所在的位置。But if you were to express the same instruction to a robot, or a computer program, you would have to start with the location before indicating what can be obtained from that location. 但是,如果要向机器人或计算机程序表达相同的指令,则必须先从位置开始,然后才能指示可以从该位置获得什么。Your instruction might have been something like, “Go to the kitchen; open the top-left drawer; grab the car keys; bring them to me.” 你的指示可能是这样的:“去厨房,打开左上方的抽屉,抓起车钥匙,拿给我。”The keyed-in order of the query clauses is similar to English—it starts with the 查询子句的键控顺序类似于英语,它以SELECT clause. SELECT子句开头。Logical query processing order is similar to how you provide instructions to a computer program—with the 逻辑查询处理顺序类似于先处理FROM clause processed first.FROM子句,然后向计算机程序提供指令的方式。
Now that you understand the order in which the query clauses are logically processed, the next sections explain the details of each phase.现在您已经了解了查询子句的逻辑处理顺序,接下来的部分将解释每个阶段的细节。
When discussing logical query processing, I refer to query 在讨论逻辑查询处理时,我指的是查询子句和查询阶段(例如clauses and query phases (the WHERE clause and the WHERE phase, for example). WHERE子句和WHERE阶段)。A query clause is a syntactical component of a query, so when discussing the syntax of a query element I usually use the term 查询子句是查询的一个语法组件,因此在讨论查询元素的语法时,我通常使用术语“子句”,例如,“在clause—for example, “In the WHERE clause, you specify a predicate.” WHERE子句中,指定一个谓词。”When discussing the logical manipulation taking place as part of logical query processing, I usually use the term 在讨论作为逻辑查询处理的一部分进行的逻辑操作时,我通常使用术语“阶段”,例如,“phase—for example, “The WHERE phase returns rows for which the predicate evaluates to TRUE.”WHERE阶段返回谓词计算为TRUE的行”。
Recall my recommendation from the previous chapter regarding the use of a semicolon to terminate statements. 回想一下我在上一章中关于使用分号终止语句的建议。At the moment, Microsoft SQL Server doesn't require you to terminate all statements with a semicolon. 目前,Microsoft SQL Server不要求您用分号终止所有语句。This is a requirement only in particular cases where the parsing of the code might otherwise be ambiguous. 只有在代码解析可能模棱两可的特定情况下,才需要这样做。However, I recommend you terminate all statements with a semicolon because it is standard, it improves the code readability, and it is likely that SQL Server will require this in more—if not all—cases in the future. 但是,我建议您用分号终止所有语句,因为它是标准的,可以提高代码的可读性,而且SQL Server将来可能会在更多情况下(如果不是所有情况的话)需要使用分号。Currently, when a semicolon is not required, adding one doesn't interfere.目前,当不需要分号时,添加分号不会产生干扰。
FROM clauseFROM子句The FROM clause is the very first query clause that is logically processed. FROM子句是第一个经过逻辑处理的查询子句。In this clause, you specify the names of the tables you want to query and table operators that operate on those tables. 在本子句中,指定要查询的表的名称以及对这些表进行操作的表运算符。This chapter doesn't get into table operators; I describe those in Chapters 3, 5, and 7. 本章不涉及表运算符;我在第3章、第5章和第7章中描述了这些。For now, you can just consider the 现在,您可以只考虑FROM clause to be simply where you specify the name of the table you want to query. FROM子句,简单地指定您要查询的表的名称。The sample query in Listing 2-1 queries the Listing 2-1中的示例查询查询Orders table in the Sales schema, finding 830 rows.Sales架构中的Orders表,找到830行。
FROM Sales.Orders
Recall the recommendation I gave in the previous chapter to always schema-qualify object names in your code. 回想一下我在上一章中给出的建议,即在代码中始终使用模式限定对象名称。When you don't specify the schema name explicitly, SQL Server must resolve it implicitly based on its implicit name-resolution rules. 如果不显式指定架构名称,SQL Server必须根据其隐式名称解析规则隐式解析它。This creates some minor cost and can result in SQL Server choosing a different object than the one you intended. 这会产生一些较小的成本,并可能导致SQL Server选择与预期不同的对象。By being explicit, your code is safer in the sense you ensure that you get the object you intended to get. 通过显式,您的代码更安全,因为您可以确保获得预期的对象。Plus, you don't pay any unnecessary penalties.此外,你不需要支付任何不必要的罚款。
To return all rows from a table with no special manipulation, all you need is a query with a 要在不进行特殊操作的情况下返回表中的所有行,只需使用一个带有FROM clause in which you specify the table you want to query, and a SELECT clause in which you specify the attributes you want to return. FROM子句的查询,其中指定要查询的表,以及一个SELECT子句,其中指定要返回的属性。For example, the following statement queries all rows from the 例如,下面的语句查询Orders table in the Sales schema, selecting the attributes orderid, custid, empid, orderdate, and freight.Sales架构中Orders表中的所有行,选择orderid、custid、empid、orderdate和freight属性。
SELECT orderid, custid, empid, orderdate, freight
FROM Sales.Orders;
The output of this statement is shown here in abbreviated form:此语句的输出以缩写形式显示:
orderid custid empid orderdate freight
----------- ----------- ----------- ---------- ---------------------
10248 85 5 2014-07-04 32.38
10249 79 6 2014-07-05 11.61
10250 34 4 2014-07-08 65.83
10251 84 3 2014-07-08 41.34
10252 76 4 2014-07-09 51.30
10253 34 3 2014-07-10 58.17
10254 14 5 2014-07-11 22.98
10255 68 9 2014-07-12 148.33
10256 88 3 2014-07-15 13.97
10257 35 4 2014-07-16 81.91
...
(830 row(s) affected)
Although it might seem that the output of the query is returned in a particular order, this is not guaranteed. 尽管查询的输出似乎是按特定顺序返回的,但这并不能保证。I'll elaborate on this point later in this chapter, in the sections “The 我将在本章后面的“SELECT clause” and “The ORDER BY clause.”SELECT子句”和“ORDER BY子句”部分详细阐述这一点。
WHERE clauseWHERE子句In the 在WHERE clause, you specify a predicate or logical expression to filter the rows returned by the FROM phase. WHERE子句中,指定一个谓词或逻辑表达式来筛选FROM阶段返回的行。Only rows for which the logical expression evaluates to TRUE are returned by the WHERE phase to the subsequent logical query processing phase. WHERE阶段仅将逻辑表达式计算结果为TRUE的行返回到后续逻辑查询处理阶段。In the sample query in Listing 2-1, the 在Listing 2-1中的示例查询中,WHERE phase filters only orders placed by customer 71:WHERE阶段只筛选客户71下的订单:
FROM Sales.Orders
WHERE custid = 71
Out of the 830 rows returned by the 在FROM phase, the WHERE phase filters only the 31 rows where the customer ID is equal to 71. FROM阶段返回的830行中,WHERE阶段只筛选客户ID等于71的31行。To see which rows you get back after applying the filter 要查看应用筛选器custid = 71, run the following query:custid=71后返回的行,请运行以下查询:
SELECT orderid, empid, orderdate, freight
FROM Sales.Orders
WHERE custid = 71;
This query generates the following output:此查询生成以下输出:
orderid empid orderdate freight
----------- ----------- ---------- --------
10324 9 2014-10-08 214.27
10393 1 2014-12-25 126.56
10398 2 2014-12-30 89.16
10440 4 2015-02-10 86.53
10452 8 2015-02-20 140.26
10510 6 2015-04-18 367.63
10555 6 2015-06-02 252.49
10603 8 2015-07-18 48.77
10607 5 2015-07-22 200.24
10612 1 2015-07-28 544.08
10627 8 2015-08-11 107.46
10657 2 2015-09-04 352.69
10678 7 2015-09-23 388.98
10700 3 2015-10-10 65.10
10711 5 2015-10-21 52.41
10713 1 2015-10-22 167.05
10714 5 2015-10-22 24.49
10722 8 2015-10-29 74.58
10748 3 2015-11-20 232.55
10757 6 2015-11-27 8.19
10815 2 2016-01-05 14.62
10847 4 2016-01-22 487.57
10882 4 2016-02-11 23.10
10894 1 2016-02-18 116.13
10941 7 2016-03-11 400.81
10983 2 2016-03-27 657.54
10984 1 2016-03-30 211.22
11002 4 2016-04-06 141.16
11030 7 2016-04-17 830.75
11031 6 2016-04-17 227.22
11064 1 2016-05-01 30.09
(31 row(s) affected)
The WHERE clause has significance when it comes to query performance. WHERE子句在查询性能方面具有重要意义。Based on what you have in the filter expression, SQL Server evaluates the use of indexes to access the required data. 根据筛选器表达式中的内容,SQL Server会评估索引的使用情况,以访问所需的数据。By using indexes, SQL Server can sometimes get the required data with much less work compared to applying full table scans. 通过使用索引,SQL Server有时可以用比应用全表扫描少得多的工作来获取所需的数据。Query filters also reduce the network traffic created by returning all possible rows to the caller and filtering on the client side.查询筛选器还通过将所有可能的行返回给调用者并在客户端进行过滤来减少网络流量。
Earlier, I mentioned that only rows for which the logical expression evaluates to 前面我提到,TRUE are returned by the WHERE phase. WHERE阶段只返回逻辑表达式计算结果为TRUE的行。Always keep in mind that T-SQL uses three-valued predicate logic, where logical expressions can evaluate to 请始终记住,T-SQL使用三值谓词逻辑,其中逻辑表达式的计算结果可以为TRUE, FALSE, or UNKNOWN. TRUE、FALSE或UNKNOWN。With three-valued logic, saying “returns 在三值逻辑中,说“返回TRUE” is not the same as saying “does not return FALSE.” TRUE”与说“不返回FLASE”并不相同The WHERE phase returns rows for which the logical expression evaluates to TRUE, and it doesn't return rows for which the logical expression evaluates to FALSE or UNKNOWN. WHERE阶段返回逻辑表达式计算为TRUE的行,而不返回逻辑表达式计算为FALSE或UNKNOWN的行。I elaborate on this point later in this chapter in the section “我将在本章后面的“NULL”部分详细阐述这一点NULLs.”
GROUP BY clauseGROUP BY子句You can use the 可以使GROUP BY phase to arrange the rows returned by the previous logical query processing phase in groups. GROUP BY阶段将上一个逻辑查询处理阶段返回的行分组排列。The groups are determined by the elements you specify in the 这些组由您在GROUP BY clause. GROUP BY子句中指定的元素决定。For example, the 例如,Listing 2-1中查询中的GROUP BY clause in the query in Listing 2-1 has the elements empid and YEAR(orderdate):GROUP BY子句包含元素empid和YEAR(orderdate):
FROM Sales.Orders
WHERE custid = 71
GROUP BY empid, YEAR(orderdate)
This means that the 这意味着GROUP BY phase produces a group for each unique combination of employee-ID and order-year values that appears in the data returned by the WHERE phase. GROUP BY阶段为WHERE阶段返回的数据中显示的员工ID和订单年份值的每个唯一组合生成一个组。The expression 表达式YEAR(orderdate) invokes the YEAR function to return only the year part from the orderdate column.YEAR(orderdate)调用YEAR函数,只返回orderdate列中的年份部分。
The WHERE phase returned 31 rows, within which there are 16 unique combinations of employee-ID and order-year values, as shown here:WHERE阶段返回31行,其中有16个员工ID和订单年份值的唯一组合,如下所示:
empid YEAR(orderdate)
----------- ---------------
1 2014
1 2015
1 2016
2 2014
2 2015
2 2016
3 2015
4 2015
4 2016
5 2015
6 2015
6 2016
7 2015
7 2016
8 2015
9 2014
Thus, the 因此,GROUP BY phase creates 16 groups and associates each of the 31 rows returned from the WHERE phase with the relevant group.GROUP BY阶段创建16个组,并将WHERE阶段返回的31行中的每一行与相关组相关联。
If the query involves grouping, all phases subsequent to the 如果查询涉及分组,则GROUP BY phase—including HAVING, SELECT, and ORDER BY—must operate on groups as opposed to operating on individual rows. GROUP BY阶段之后的所有阶段(包括HAVING、SELECT和ORDER BY)都必须对组进行操作,而不是对单个行进行操作。Each group is ultimately represented by a single row in the final result of the query. 在查询的最终结果中,每个组最终由一行表示。This implies that all expressions you specify in clauses that are processed in phases subsequent to the 这意味着您在子句中指定的所有表达式都需要在GROUP BY phase are required to guarantee returning a scalar (single value) per group.GROUP BY阶段之后的阶段中处理,以保证每个组返回标量(单个值)。
Expressions based on elements that participate in the 基于参与GROUP BY clause meet the requirement because, by definition, each group has only one unique occurrence of each GROUP BY element. GROUP BY子句的元素的表达式符合要求,因为根据定义,每个GROUP BY元素只有一个唯一的引用。For example, in the group for employee ID 8 and order year 2015, there's only one unique employee-ID value and only one unique order-year value. 例如,在员工ID 8和订单年份2015的组中,只有一个唯一的员工ID值和一个唯一的订单年份值。Therefore, you're allowed to refer to the expressions 因此,您可以在子句中引用表达式empid and YEAR(orderdate) in clauses that are processed in phases subsequent to the GROUP BY phase, such as the SELECT clause. empid和YEAR(orderdate),这些子句在GROUP BY阶段之后的阶段中处理,例如SELECT子句。The following query, for example, returns 16 rows for the 16 groups of employee-ID and order-year values:例如,以下查询为16组员工ID和订单年份值返回16行:
SELECT empid, YEAR(orderdate) AS orderyear
FROM Sales.Orders
WHERE custid = 71
GROUP BY empid, YEAR(orderdate);
This query returns the following output:此查询返回以下输出:
empid orderyear
----------- -----------
1 2014
1 2015
1 2016
2 2014
2 2015
2 2016
3 2015
4 2015
4 2016
5 2015
6 2015
6 2016
7 2015
7 2016
8 2015
9 2014
(16 row(s) affected)
Elements that do not participate in the 不参与GROUP BY clause are allowed only as inputs to an aggregate function such as COUNT, SUM, AVG, MIN, or MAX. GROUP BY子句的元素只允许作为聚合函数的输入,例如COUNT、SUM、AVG、MIN或MAX。For example, the following query returns the total freight and number of orders per employee and order year:例如,以下查询返回每个员工和订单年的总运费和订单数:
SELECT
empid,
YEAR(orderdate) AS orderyear,
SUM(freight) AS totalfreight,
COUNT(*) AS numorders
FROM Sales.Orders
WHERE custid = 71
GROUP BY empid, YEAR(orderdate);
This query generates the following output:此查询生成以下输出:
empid orderyear totalfreight numorders
----------- ----------- --------------------- -----------
1 2014 126.56 1
2 2014 89.16 1
9 2014 214.27 1
1 2015 711.13 2
2 2015 352.69 1
3 2015 297.65 2
4 2015 86.53 1
5 2015 277.14 3
6 2015 628.31 3
7 2015 388.98 1
8 2015 371.07 4
1 2016 357.44 3
2 2016 672.16 2
4 2016 651.83 3
6 2016 227.22 1
7 2016 1231.56 2
(16 row(s) affected)
The expression 表达式SUM(freight) returns the sum of all freight values in each group, and the function COUNT(*) returns the count of rows in each group—which in this case means the number of orders. SUM(freight)返回每个组中所有运费值的总和,函数COUNT(*)返回每个组中的行数,在本例中表示订单数。If you try to refer to an attribute that does not participate in the 如果您试图引用一个不参与GROUP BY clause (such as freight) and not as an input to an aggregate function in any clause that is processed after the GROUP BY clause, you get an error—in such a case, there's no guarantee that the expression will return a single value per group. GROUP BY子句的属性(例如freight),而不是在GROUP BY子句之后处理的任何子句中作为聚合函数的输入,那么在这种情况下,您会得到一个错误,不能保证表达式会在每个组中返回一个值。For example, the following query will fail:例如,以下查询将失败:
SELECT empid, YEAR(orderdate) AS orderyear, freight
FROM Sales.Orders
WHERE custid = 71
GROUP BY empid, YEAR(orderdate);
SQL Server produces the following error:SQL Server产生以下错误:
Msg 8120, Level 16, State 1, Line 1
Column Sales.Orders.freight' is invalid in the select list because it is not contained in
either an aggregate function or the GROUP BY clause.
Note that all aggregate functions ignore 请注意,所有聚合函数都忽略NULLs, with one exception—COUNT(*). NULL值,只有一个例外,即COUNT(*)。For example, consider a group of five rows with the values 例如,在一个名为30, 10, NULL, 10, 10 in a column called qty. qty的列中考虑一组五行,值为30, 10,NULL,10, 10。The expression 表达式COUNT(*) returns 5 because there are five rows in the group, whereas COUNT(qty) returns 4 because there are four known values. COUNT(*)返回5,因为组中有五行,而COUNT(qty)返回4,因为有四个已知值。If you want to handle only distinct occurrences of known values, specify the 如果只希望处理已知值的不同出现,请在聚合函数的输入表达式之前指定DISTINCT keyword before the input expression to the aggregate function. DISTINCT关键字。For example, the expression 例如,表达式COUNT(DISTINCT qty) returns 2, because there are two distinct known values (30 and 10). COUNT(DISTINCT qty)返回2,因为有两个不同的已知值(30和10)。The DISTINCT keyword can be used with other functions as well. DISTINCT关键字也可以用于其他函数。For example, although the expression 例如,尽管表达式SUM(qty) returns 60, the expression SUM(DISTINCT qty) returns 40. SUM(qty)返回60,但表达式SUM(DISTINCT qty)返回40。The expression 表达式AVG(qty) returns 15, whereas the expression AVG(DISTINCT qty) returns 20. AVG(qty)返回15,而表达式AVG(DISTINCT qty)返回20。As an example of using the 作为在完整查询中使用DISTINCT option with an aggregate function in a complete query, the following code returns the number of distinct (unique) customers handled by each employee in each order year:DISTINCT选项和聚合函数的示例,以下代码返回每个员工在每个订单年处理的不同(唯一)客户数:
SELECT
empid,
YEAR(orderdate) AS orderyear,
COUNT(DISTINCT custid) AS numcusts
FROM Sales.Orders
GROUP BY empid, YEAR(orderdate);
This query generates the following output:此查询生成以下输出:
empid orderyear numcusts
----------- ----------- -----------
1 2014 22
2 2014 15
3 2014 16
4 2014 26
5 2014 10
6 2014 15
7 2014 11
8 2014 19
9 2014 5
1 2015 40
2 2015 35
3 2015 46
4 2015 57
5 2015 13
6 2015 24
7 2015 30
8 2015 36
9 2015 16
1 2016 32
2 2016 34
3 2016 30
4 2016 33
5 2016 11
6 2016 17
7 2016 21
8 2016 23
9 2016 16
(27 row(s) affected)
HAVING clauseHAVING子句Whereas the WHERE clause is a row filter, the HAVING clause is a group filter. WHERE子句是行筛选器,HAVING子句是组筛选器。Only groups for which the HAVING predicate evaluates to TRUE are returned by the HAVING phase to the next logical query processing phase. HAVING阶段只将HAVING谓词计算为TRUE的组返回到下一个逻辑查询处理阶段。Groups for which the predicate evaluates to 谓词的计算结果为FALSE or UNKNOWN are discarded.FALSE或UNKNOWN的组将被丢弃。
Because the 因为HAVING clause is processed after the rows have been grouped, you can refer to aggregate functions in the logical expression. HAVING子句是在对行进行分组后处理的,所以可以在逻辑表达式中引用聚合函数。For example, in the query from Listing 2-1, the 例如,在Listing 2-1中的查询中,HAVING clause has the logical expression COUNT(*) > 1, meaning that the HAVING phase filters only groups (employee and order year) with more than one row. HAVING子句的逻辑表达式COUNT(*) > 1,这意味着HAVING阶段只筛选具有多行的组(员工和订单年)。The following fragment of the Listing 2-1 query shows the steps that have been processed so far:Listing 2-1查询的以下片段显示了迄今为止已处理的步骤:
FROM Sales.Orders
WHERE custid = 71
GROUP BY empid, YEAR(orderdate)
HAVING COUNT(*) > 1
Recall that the 回想一下,GROUP BY phase created 16 groups of employee ID and order year. GROUP BY阶段创建了16组员工ID和订单年份。Seven of those groups have only one row, so after the 其中七个组只有一行,因此在处理HAVING clause is processed, nine groups remain. Run the following query to return those nine groups:HAVING子句之后,剩下九个组。运行以下查询以返回这九个组:
SELECT empid, YEAR(orderdate) AS orderyear
FROM Sales.Orders
WHERE custid = 71
GROUP BY empid, YEAR(orderdate)
HAVING COUNT(*) > 1;
This query returns the following output:此查询返回以下输出:
empid orderyear
----------- -----------
1 2015
3 2015
5 2015
6 2015
8 2015
1 2016
2 2016
4 2016
7 2016
(9 row(s) affected)
SELECT clauseSELECT子句The SELECT clause is where you specify the attributes (columns) you want to return in the result table of the query. SELECT子句用于指定要在查询的结果表中返回的属性(列)。You can base the expressions in the 您可以根据查询表中的属性创建SELECT list on attributes from the queried tables, with or without further manipulation.SELECT列表中的表达式,无论是否进行进一步操作。
For example, the 例如,Listing 2-1中的选择列表有以下表达式:SELECT list in Listing 2-1 has the following expressions: empid, YEAR(orderdate), and COUNT(*). empid、YEAR(orderdate)和COUNT(*)。If an expression refers to an attribute with no manipulation, such as 如果表达式引用的属性没有进行任何操作,例如empid, the name of the target attribute is the same as the name of the source attribute. empid,则目标属性的名称与源属性的名称相同。You can optionally assign your own name to the target attribute by using the 您可以选择使用AS clause—for example, empid AS employee_id. AS子句将自己的名称指定给目标属性,例如empid AS employee_id。Expressions that do apply manipulation, such as 确实应用了操作的表达式(如YEAR(orderdate), or that are not based on a source attribute, such as a call to the function SYSDATETIME, won't have a name unless you alias them. YEAR(orderdate))或不基于源属性的表达式(如对函数SYSDATETIME的调用)将没有名称,除非您为它们加上别名。T-SQL allows a query to return result columns with no names in certain cases, but the relational model doesn't. 在某些情况下,T-SQL允许查询返回没有名称的结果列,但关系模型不允许。I recommend you alias such expressions as 我建议您将YEAR(orderdate) AS orderyear so that all result attributes have names. YEAR(orderdate)等表达式别名为orderyear,以便所有结果属性都有名称。In this respect, the result table returned from the query would be considered relational.在这方面,从查询返回的结果表将被视为关系表。
In addition to supporting the 除了支持AS clause, T-SQL supports a couple of other forms with which you can alias expressions. AS子句外,T-SQL还支持两种其他形式,您可以使用它们来别名表达式。To me, the 在我看来,AS clause seems the most readable and intuitive form; therefore, I recommend using it. AS子句似乎是最可读和最直观的形式;因此,我建议使用它。I will cover the other forms for the sake of completeness and also to describe an elusive bug related to one of them.为了完整起见,我将介绍其他表单,并描述与其中一个表单相关的难以捉摸的错误。
In addition to supporting the form 除了支持形式<expression> AS <alias>, T-SQL also supports the forms <alias> = <expression> (“alias equals expression”) and <expression> <alias> (“expression space alias”). <expression> AS <alias>,T-SQL还支持形式<alias> = <expression>(“别名等于表达式”)以及<expression> <alias>(“表达式 空间别名”)。An example of the former is 前者的示例是orderyear = YEAR(orderdate), and an example of the latter is YEAR(orderdate) orderyear. orderyear=YEAR(orderdate),后者的示例是YEAR(orderdate) orderyear。I find the latter particularly unclear and recommend avoiding it, although unfortunately this form is very common in people's code.我发现后者特别不清楚,建议避免使用,但不幸的是,这种形式在人们的代码中非常常见。
Note that if by mistake you miss a comma between two column names in the 请注意,如果错误地在SELECT list, your code won't fail. SELECT列表中的两个列名之间漏掉了逗号,代码不会失败。Instead, SQL Server will assume the second name is an alias for the first column name. 相反,SQL Server将假定第二个名称是第一个列名的别名。As an example, suppose you want to query the columns 例如,假设您想从orderid and orderdate from the Sales.Orders table and you miss the comma between them, as follows:Sales.Orders表中查询orderid和orderdate列,但没有找到它们之间的逗号,如下所示:
SELECT orderid orderdate
FROM Sales.Orders;
This query is considered syntactically valid, as if you intended to alias the 此查询在语法上是有效的,就好像您打算将orderid column as orderdate. orderid列别名为orderdate一样。In the output, you will get only one column holding the order IDs, with the alias 在输出中,只有一列包含订单ID,别名为orderdate:orderdate:
orderdate
-----------
10248
10249
10250
10251
10252
...
(830 row(s) affected)
If you're accustomed to using the syntax with the space between an expression and its alias, it will be harder for you to detect such bugs.如果您习惯于使用表达式与其别名之间有空格的语法,那么您将更难检测此类错误。
With the addition of the 通过添加SELECT phase, the following query clauses from the query in Listing 2-1 have been processed so far:SELECT阶段,Listing 2-1中的查询中的以下查询子句已被处理:
SELECT empid, YEAR(orderdate) AS orderyear, COUNT(*) AS numorders
FROM Sales.Orders
WHERE custid = 71
GROUP BY empid, YEAR(orderdate)
HAVING COUNT(*) > 1
The SELECT clause produces the result table of the query. SELECT子句生成查询的结果表。In the case of the query in Listing 2-1, the heading of the result table has the attributes 对于Listing 2-1中的查询,结果表的标题具有属性empid, orderyear, and numorders, and the body has nine rows (one for each group). Run the following query to return those nine rows:empid、orderyear和numorders,正文有九行(每组一行)。运行以下查询以返回这九行:
SELECT empid, YEAR(orderdate) AS orderyear, COUNT(*) AS numorders
FROM Sales.Orders
WHERE custid = 71
GROUP BY empid, YEAR(orderdate)
HAVING COUNT(*) > 1;
This query generates the following output:此查询生成以下输出:
empid orderyear numorders
----------- ----------- -----------
1 2015 2
3 2015 2
5 2015 3
6 2015 3
8 2015 4
1 2016 3
2 2016 2
4 2016 3
7 2016 2
(9 row(s) affected)
Remember that the 请记住,SELECT clause is processed after the FROM, WHERE, GROUP BY, and HAVING clauses. SELECT子句是在FROM、WHERE、GROUP BY和HAVING子句之后处理的。This means that aliases assigned to expressions in the 这意味着,就SELECT clause do not exist as far as clauses that are processed before the SELECT clause are concerned. SELECT子句之前处理的子句而言,分配给SELECT子句中表达式的别名并不存在。It's a typical mistake to try and refer to expression aliases in clauses that are processed before the 尝试在SELECT clause, such as in the following example in which the attempt is made in the WHERE clause:SELECT子句之前处理的子句中引用表达式别名是一个典型的错误,例如在下面的示例中,尝试在WHERE子句中引用表达式别名:
SELECT orderid, YEAR(orderdate) AS orderyear
FROM Sales.Orders
WHERE orderyear > 2015;
At first glance, this query might seem valid, but if you consider that the column aliases are created in the 乍一看,这个查询看起来是有效的,但是如果您认为在SELECT phase—which is processed after the WHERE phase—you can see that the reference to the orderyear alias in the WHERE clause is invalid. SELECT阶段中创建的列别名是在WHERE阶段之后处理的,那么您可以看到对WHERE子句中的orderyear别名的引用无效。In fact, SQL Server produces the following error:实际上,SQL Server会产生以下错误:
Msg 207, Level 16, State 1, Line 3
Invalid column name 'orderyear'.
Amusingly, a lecture attendee once asked me in all seriousness when Microsoft is going to fix this bug. 有趣的是,一位参加讲座的人曾严肃地问我,微软什么时候能修复这个漏洞。As you can gather from this chapter, this behavior is not a bug; rather, it is by design. Also, it was not defined by Microsoft; rather, it was defined by the SQL standard.从本章可以看出,这种行为并不是一个bug;相反,这是出于设计。而且,它不是由微软定义的;相反,它是由SQL标准定义的。
One way around this problem is to repeat the expression 解决此问题的一种方法是在YEAR(orderdate) in both the WHERE and SELECT clauses:WHERE和SELECT子句中重复表达式YEAR(orderdate):
SELECT orderid, YEAR(orderdate) AS orderyear
FROM Sales.Orders
WHERE YEAR(orderdate) > 2015;
A similar problem can happen if you try to refer to an expression alias in the 如果尝试在HAVING clause, which is also processed before the SELECT clause:HAVING子句中引用表达式别名,也会出现类似的问题,该别名也会在SELECT子句之前处理:
SELECT empid, YEAR(orderdate) AS orderyear, COUNT(*) AS numorders
FROM Sales.Orders
WHERE custid = 71
GROUP BY empid, YEAR(orderdate)
HAVING numorders > 1;
This query fails with an error saying that the column name 此查询失败,错误提示列名numorders is invalid. numorders无效。Just like in the previous example, the workaround here is to repeat the expression 与上一个示例一样,这里的解决方法是在两个子句中重复表达式COUNT(*) in both clauses:COUNT(*):
SELECT empid, YEAR(orderdate) AS orderyear, COUNT(*) AS numorders
FROM Sales.Orders
WHERE custid = 71
GROUP BY empid, YEAR(orderdate)
HAVING COUNT(*) > 1;
In the relational model, operations on relations are based on relational algebra and result in a relation. 在关系模型中,对关系的操作基于关系代数,并产生一个关系。Recall that a relation's body is a set of tuples, and a set has no duplicates. 回想一下,一个关系的主体是一组元组,一个元组没有重复项。Unlike the relational model, which is based on mathematical set theory, SQL is based on multiset theory. 与基于数学集合论的关系模型不同,SQL基于多集理论。The mathematical term 数学术语multiset, or bag, is similar in some aspects to a set but does allow duplicates. multiset或bag在某些方面与集合相似,但允许重复。A table in SQL isn't required to have a key. Without a key, the table can have duplicate rows and therefore isn't relational. SQL中的表不需要有键。如果没有键,表可能有重复的行,因此不是关系表。Even if the table does have a key, a 即使该表确实有键,针对该表的SELECT query against the table can still return duplicate rows. SELECT查询仍然可以返回重复的行。SQL query results do not have keys. SQL查询结果没有键。As an example, the 例如,Orders table does have a primary key defined on orderid column. Orders表在orderid列上定义了一个主键。Still, the query in Listing 2-2 against the 尽管如此,Listing 2-2中针对Orders table returns duplicate rows.Orders表的查询仍会返回重复的行。
LISTING 2-2 Query returning duplicate rows返回重复行的查询
SELECT empid, YEAR(orderdate) AS orderyear
FROM Sales.Orders
WHERE custid = 71;
This query generates the following output:此查询生成以下输出:
empid orderyear
----------- -----------
9 2014
1 2014
2 2014
4 2015
8 2015
6 2015
6 2015
8 2015
5 2015
1 2015
8 2015
2 2015
7 2015
3 2015
5 2015
1 2015
5 2015
8 2015
3 2015
6 2015
2 2016
4 2016
4 2016
1 2016
7 2016
2 2016
1 2016
4 2016
7 2016
6 2016
1 2016
(31 row(s) affected)
SQL provides the means to remove duplicates using the SQL提供了使用DISTINCT clause (as shown in Listing 2-3) and, in this sense, return a relational result.DISTINCT子句删除重复项的方法(如Listing 2-3所示),并在这个意义上返回一个关系结果。
LISTING 2-3 Query with a 带DISTINCT clauseDISTINCT子句的查询
SELECT DISTINCT empid, YEAR(orderdate) AS orderyear
FROM Sales.Orders
WHERE custid = 71;
This query generates the following output:此查询生成以下输出:
empid orderyear
----------- -----------
1 2014
1 2015
1 2016
2 2014
2 2015
2 2016
3 2015
4 2015
4 2016
5 2015
6 2015
6 2016
7 2015
7 2016
8 2015
9 2014
(16 row(s) affected)
Of the 31 rows in the multiset returned by the query in Listing 2-2, 16 rows are in the set returned by the query in Listing 2-3 after the removal of duplicates.Listing 2-2中的查询返回的multiset中的31行中,删除重复项后,Listing 2-3中的查询返回的集合中有16行。
SQL allows specifying an asterisk (*) in the SQL允许在SELECT list to request all attributes from the queried tables instead of listing them explicitly, as in the following example:SELECT列表中指定星号(*),以请求查询表中的所有属性,而不是显式列出它们,如以下示例所示:
SELECT *
FROM Sales.Shippers;
Such use of an asterisk is considered a bad programming practice in most cases. 在大多数情况下,使用星号被认为是一种糟糕的编程实践。It is recommended that you explicitly list all attributes you need. Unlike with the relational model, SQL keeps ordinal positions for columns based on the order in which you specified them in the 建议您明确列出所需的所有属性。与关系模型不同,SQL根据在CREATE TABLE statement. CREATE TABLE语句中指定列的顺序为列保留顺序位置。By specifying 通过指定SELECT *, you're guaranteed to get the columns ordered in the output based on their ordinal positions. SELECT *,可以保证根据列的顺序位置对输出中的列进行排序。Client applications can refer to columns in the result by their ordinal positions (a bad practice in its own right) instead of by name. 客户端应用程序可以按顺序位置(这本身就是一种糟糕的做法)而不是按名称引用结果中的列。Then any schema changes applied to the table—such as adding or removing columns, rearranging their order, and so on—might result in failures in the client application or, even worse, in application bugs that will go unnoticed. 然后,应用于表的任何模式更改(例如添加或删除列、重新排列它们的顺序等)都可能会导致客户端应用程序失败,或者更糟的是,导致应用程序错误被忽略。By explicitly specifying the attributes you need, you always get the right ones, as long as the columns exist in the table. 通过显式指定所需的属性,只要表中存在列,就总能得到正确的属性。If a column referenced by the query was dropped from the table, you get an error and can fix your code accordingly.如果查询引用的列从表中删除,则会出现错误,可以相应地修复代码。
People often wonder whether there's any performance difference between specifying an asterisk and explicitly listing column names. 人们经常想知道指定星号和显式列出列名之间是否有性能差异。There is some extra work involved in resolving column names when the asterisk is used, but the cost is negligible compared to other costs involved in the processing of a query. 当使用星号时,解析列名会涉及一些额外的工作,但与处理查询所涉及的其他成本相比,成本可以忽略不计。Because listing column names explicitly is the recommended practice anyway, it's a win-win situation.因为明确列出列名无论如何都是推荐的做法,所以这是一种双赢的情况。
Curiously, you are not allowed to refer to column aliases created in the 奇怪的是,不允许在同一SELECT clause in other expressions within the same SELECT clause. SELECT子句中的其他表达式中引用SELECT子句中创建的列别名。That's the case even if the expression that tries to use the alias appears to the right of the expression that created it. 即使尝试使用别名的表达式出现在创建别名的表达式的右侧,情况也是如此。For example, the following attempt is invalid:例如,以下尝试无效:
SELECT orderid,
YEAR(orderdate) AS orderyear,
orderyear + 1 AS nextyear
FROM Sales.Orders;
I'll explain the reason for this restriction later in this chapter, in the section, “All-at-Once Operations.” 我将在本章后面的“一次性操作”一节中解释这种限制的原因As explained earlier in this section, one of the ways around this problem is to repeat the expression:如本节前面所述,解决此问题的方法之一是重复以下表达式:
SELECT orderid,
YEAR(orderdate) AS orderyear,
YEAR(orderdate) + 1 AS nextyear
FROM Sales.Orders;
ORDER BY clauseORDER BY子句You use the 为了便于演示,可以使用ORDER BY clause to sort the rows in the output for presentation purposes. ORDER BY子句对输出中的行进行排序。In terms of logical query processing, 在逻辑查询处理方面,ORDER BY is the very last clause to be processed. ORDER BY是最后一个要处理的子句。The sample query shown in Listing 2-4 sorts the rows in the output by employee ID and order year.Listing 2-4所示的示例查询按员工ID和订单年份对输出中的行进行排序。
LISTING 2-4 Query demonstrating the 演示ORDER BY clauseORDER BY子句的查询
SELECT empid, YEAR(orderdate) AS orderyear, COUNT(*) AS numorders
FROM Sales.Orders
WHERE custid = 71
GROUP BY empid, YEAR(orderdate)
HAVING COUNT(*) > 1
ORDER BY empid, orderyear;
This query generates the following output:此查询生成以下输出:
empid orderyear numorders
----------- ----------- -----------
1 2015 2
1 2016 3
2 2016 2
3 2015 2
4 2016 3
5 2015 3
6 2015 3
7 2016 2
8 2015 4
(9 row(s) affected)
This time, presentation ordering in the output is guaranteed—unlike with queries that don't have a presentation 这一次,与没有演示ORDER BY clause.ORDER BY子句的查询不同,可以保证输出中的表示顺序。
One of the most important points to understand about SQL is that a table—be it an existing table in the database or a table result returned by a query—has no guaranteed order. 了解SQL最重要的一点是,表(无论是数据库中的现有表还是查询返回的表结果)没有保证顺序。That's because a table is supposed to represent a set of rows (or multiset, if it has duplicates), and a set has no order. 这是因为一个表应该表示一组行(或者多集,如果它有重复项),而一个集没有顺序。This means that when you query a table without specifying an 这意味着,当您在不指定ORDER BY clause, SQL Server is free to return the rows in the output in any order. ORDER BY子句的情况下查询表时,SQL Server可以自由地以任何顺序返回输出中的行。The only way for you to guarantee the presentation order in the result is with an 保证结果中呈现顺序的唯一方法是使用ORDER BY clause. ORDER BY子句。However, you should realize that if you do specify an 但是,您应该意识到,如果您确实指定了ORDER BY clause, the result can't qualify as a table because it is ordered. ORDER BY子句,那么结果就不能作为表,因为它是有序的。Standard SQL calls such a result a 标准SQL将这样的结果称为游标。cursor.
You're probably wondering why it matters whether a query returns a table or a cursor. 您可能想知道为什么查询返回表还是游标很重要。Some language elements and operations in SQL expect to work with table results of queries and not with cursors. SQL中的一些语言元素和操作希望使用查询的表结果,而不是游标。Examples include table expressions and set operators, which I cover in detail in Chapter 5, “Table expressions,” and in Chapter 6, “Set operators.”示例包括表表达式和集合运算符,我在第5章“表表达式”和第6章“集合运算符”中详细介绍了它们
Notice in the query in Listing 2-4 that the 请注意,在Listing 2-4中的查询中,ORDER BY clause refers to the column alias orderyear, which was created in the SELECT phase. ORDER BY子句引用了在SELECT阶段创建的列别名orderyear。The ORDER BY phase is the only phase in which you can refer to column aliases created in the SELECT phase, because it is the only phase processed after the SELECT phase. ORDER BY阶段是唯一可以引用在SELECT阶段中创建的列别名的阶段,因为它是在SELECT阶段之后处理的唯一阶段。Note that if you define a column alias that is the same as an underlying column name, as in 请注意,如果定义了与基础列名相同的列别名,如1 - col1 AS col1, and refer to that alias in the ORDER BY clause, the new column is the one considered for ordering.1-col1 as col1中所述,并在ORDER BY子句中引用该别名,则新列就是考虑排序的列。
When you want to sort by an expression in ascending order, you either specify 如果要按表达式升序排序,可以在表达式后面指定ASC right after the expression, as in orderyear ASC, or don't specify anything after the expression, because ASC is the default. ASC,就像在orderyear ASC中一样,或者不在表达式后面指定任何内容,因为ASC是默认值。If you want to sort in descending order, you need to specify 如果要按降序排序,需要在表达式后指定DESC after the expression, as in orderyear DESC.DESC,如orderyear DESC。
With T-SQL, you can specify ordinal positions of columns in the 使用T-SQL,可以根据列在ORDER BY clause, based on the order in which the columns appear in the SELECT list. SELECT列表中的显示顺序,在ORDER BY子句中指定列的顺序位置。For example, in the query in Listing 2-4, instead of using例如,在Listing 2-4中的查询中,可以使用
ORDER BY empid, orderyear
you could use但你还可以使用
ORDER BY 1, 2
However, this is considered bad programming practice for a couple of reasons. 然而,出于几个原因,这被认为是糟糕的编程实践。First, in the relational model, attributes don't have ordinal positions and need to be referred to by name. 首先,在关系模型中,属性没有顺序位置,需要按名称引用。Second, when you make revisions to the 其次,在对SELECT clause, you might forget to make the corresponding revisions in the ORDER BY clause. SELECT子句进行修订时,可能会忘记对ORDER BY子句进行相应的修订。When you use column names, your code is safe from this type of mistake.使用列名时,代码不会出现这种错误。
With T-SQL, you also can specify elements in the 使用T-SQL,您还可以在ORDER BY clause that do not appear in the SELECT clause, meaning you can sort by something you don't necessarily want to return. ORDER BY子句中指定SELECT子句中未出现的元素,这意味着您可以按不一定要返回的内容进行排序。The big drawback for this is that you can't check your sorted results by looking at the query output. 这样做的最大缺点是无法通过查看查询输出来检查已排序的结果。For example, the following query sorts the employee rows by hire date without returning the 例如,以下查询按雇用日期对员工行进行排序,但不返回hiredate attribute:hiredate属性:
SELECT empid, firstname, lastname, country
FROM HR.Employees
ORDER BY hiredate;
However, when the 但是,当指定DISTINCT clause is specified, you are restricted in the ORDER BY list only to elements that appear in the SELECT list. DISTINCT子句时,ORDER BY列表中仅限于SELECT列表中出现的元素。The reasoning behind this restriction is that when 这种限制背后的原因是,当指定DISTINCT is specified, a single result row might represent multiple source rows; therefore, it might not be clear which of the values in the multiple rows should be used. DISTINCT时,单个结果行可能代表多个源行;因此,可能不清楚应该使用多行中的哪些值。Consider the following invalid query:考虑以下无效查询:
SELECT DISTINCT country
FROM HR.Employees
ORDER BY empid;
There are nine employees in the Employees table—five from the United States and four from the United Kingdom. Employees表中有九名员工,五名来自美国,四名来自英国。If you omit the invalid 如果在这个查询中省略了无效的ORDER BY clause from this query, you get two rows back—one for each distinct country. ORDER BY子句,则返回两行,每行对应一个不同的国家。Because each country appears in multiple rows in the source table, and each such row has a different employee ID, the meaning of 由于每个国家/地区都出现在源表的多行中,并且每一行都有不同的员工ID,因此没有真正定义ORDER BY empid is not really defined.ORDER BY empid的含义。
TOP and OFFSET-FETCH filtersTOP和OFFSET-FETCH筛选器Earlier in this chapter I covered the filtering clauses 在本章前面,我介绍了基于谓词的WHERE and HAVING, which are based on predicates. WHERE和HAVING筛选子句。In this section I cover the filtering clauses 在本节中,我将介绍基于行数和顺序的筛选子句TOP and OFFSET-FETCH, which are based on number of rows and ordering.TOP和OFFSET-FETCH。
TOP filterTOP筛选器The TOP filter is a proprietary T-SQL feature you can use to limit the number or percentage of rows your query returns. TOP筛选器是一个专有的T-SQL功能,可以用来限制查询返回的行数或百分比。It relies on two elements as part of its specification: one is the number or percent of rows to return, and the other is the ordering. 它依赖于两个元素作为其规范的一部分:一个是要返回的行数或百分比,另一个是排序。For example, to return from the 例如,要从Orders table the five most recent orders, you specify TOP (5) in the SELECT clause and orderdate DESC in the ORDER BY clause, as shown in Listing 2-5.Orders表返回最近的五个订单,可以在SELECT子句中指定TOP (5),在ORDER BY子句中指定orderdate DESC,如Listing 2-5所示。
LISTING 2-5 Query demonstrating the 演示TOP filterTOP筛选器的查询
SELECT TOP (5) orderid, orderdate, custid, empid
FROM Sales.Orders
ORDER BY orderdate DESC;
This query returns the following output:此查询返回以下输出:
orderid orderdate custid empid
----------- ---------- ----------- -----------
11077 2016-05-06 65 1
11076 2016-05-06 9 4
11075 2016-05-06 68 8
11074 2016-05-06 73 7
11073 2016-05-05 58 2
(5 row(s) affected)
Remember that the 记住,ORDER BY clause is evaluated after the SELECT clause, which includes the DISTINCT option. ORDER BY子句是在SELECT子句之后计算的,SELECT子句包括DISTINCT选项。The same is true with the TOP filter, which relies on the ORDER BY specification to give it its filtering-related meaning. TOP筛选器也是如此,它依赖于ORDER BY规范文档赋予其筛选相关的含义。This means that if 这意味着,如果DISTINCT is specified in the SELECT clause, the TOP filter is evaluated after duplicate rows have been removed.SELECT子句中指定了DISTINCT,则在删除重复行后,将对TOP筛选器进行计算。
Also note that when the 还要注意的是,当指定TOP filter is specified, the ORDER BY clause serves a dual purpose in the query. TOP筛选器时,ORDER BY子句在查询中有双重用途。One purpose is to define the presentation ordering for the rows in the query result. 一个目的是为查询结果中的行定义表示顺序。Another purpose is to define for the 另一个目的是为TOP option which rows to filter. TOP选项定义要筛选的行。For example, the query in Listing 2-5 returns the five rows with the most recent 例如,Listing 2-5中的查询返回带有最新orderdate values and presents the rows in the output in orderdate DESC ordering.orderdate值的五行,并在orderdate DESC排序中显示输出中的行。
If you're confused about whether a 如果您对TOP query returns a table result or a cursor, you have every reason to be. TOP查询是返回表结果还是返回游标感到困惑,那么您完全有理由这么做。Normally, a query with an 通常,带有ORDER BY clause returns a cursor—not a relational result. ORDER BY子句的查询会返回游标,而不是关系结果。But what if you need to filter rows with the 但是,如果需要根据某种顺序使用TOP option based on some ordering but still return a relational result? TOP选项筛选行,但仍然返回一个关系结果,该怎么办?Also, what if you need to filter rows with the 此外,如果需要根据一个顺序使用TOP option based on one order but present the output rows in another order?TOP选项筛选行,但按另一个顺序显示输出行,该怎么办?
To achieve this, you have to use a table expression, but I'll save the discussion about table expressions for Chapter 5. 要实现这一点,必须使用表表达式,但我将在第5章中保留关于表表达式的讨论。All I want to say for now is that if the design of the 现在我想说的是,如果TOP filter seems confusing, there's a good reason. TOP筛选器的设计看起来令人困惑,那么有一个很好的理由。In other words, it's not you—it's the feature's design. 换句话说,不是你,而是功能的设计。It would have been nice if the 如果TOP filter had its own ordering specification that was separate from the presentation ordering specification in the query. TOP筛选器有自己的排序规范,与查询中的表示排序规范分开,那就更好了。Unfortunately, that ship has sailed already.不幸的是,那艘船已经开航了。
You can use the 您可以将TOP option with the PERCENT keyword, in which case SQL Server calculates the number of rows to return based on a percentage of the number of qualifying rows, rounded up. TOP选项与PERCENT关键字一起使用,在这种情况下,SQL Server会根据符合条件的行数的百分比(向上舍入)计算要返回的行数。For example, the following query requests the top 1 percent of the most recent orders:例如,以下查询请求最新订单的前1%:
SELECT TOP (1) PERCENT orderid, orderdate, custid, empid
FROM Sales.Orders
ORDER BY orderdate DESC;
This query generates the following output:此查询生成以下输出:
orderid orderdate custid empid
----------- ---------- ----------- -----------
11074 2016-05-06 73 7
11075 2016-05-06 68 8
11076 2016-05-06 9 4
11077 2016-05-06 65 1
11070 2016-05-05 44 2
11071 2016-05-05 46 1
11072 2016-05-05 20 4
11073 2016-05-05 58 2
11067 2016-05-04 17 1
(9 row(s) affected)
The query returns nine rows because the 查询返回9行,因为Orders table has 830 rows, and 1 percent of 830, rounded up, is 9.Orders表有830行,830行中的1%向上取整为9。
In the query in Listing 2-5, you might have noticed that the 在Listing 2-5中的查询中,您可能已经注意到ORDER BY list is not unique (because no primary key or unique constraint is defined on the orderdate column). ORDER BY列表不是唯一的(因为orderdate列上没有定义主键或唯一约束)。Multiple rows can have the same order date. 多行可以具有相同的订单日期。In such a case, the ordering among rows with the same order date is undefined. 在这种情况下,具有相同订单日期的行之间的排序是未定义的。This fact makes the query nondeterministic—more than one result can be considered correct. 这一事实使得查询不确定性——不止一个结果被认为是正确的。In case of ties, SQL Server filters rows based on physical access order.如果是绑定,SQL Server会根据物理访问顺序筛选行。
Note that you can even use the 请注意,您甚至可以在TOP filter in a query without an ORDER BY clause. TOP中使用顶部筛选器,而无需ORDER BY子句。In such a case, the ordering is completely undefined—SQL Server returns whichever 在这种情况下,排序是完全未定义的,SQL Server将返回它首先物理访问的任意n rows it happens to physically access first, where n is the requested number of rows.n行,其中n是请求的行数。
Notice in the output for the query in Listing 2-5 that the minimum order date in the rows returned is May 5, 2016, and one row in the output has that date.请注意,在Listing 2-5中查询的输出中,返回的行中的最小订单日期是2016年5月5日,输出中有一行有该日期。 Other rows in the table might have the same order date, and with the existing non-unique 表中的其他行可能具有相同的订单日期,并且对于现有的非唯一ORDER BY list, there is no guarantee which one will be returned.ORDER BY列表,无法保证返回哪一行。
If you want the query to be deterministic, you need to make the 如果希望查询具有确定性,则需要使ORDER BY list unique; in other words, add a tiebreaker. ORDER BY列表唯一;换言之,添加一个取胜器。For example, you can add 例如,您可以将orderid DESC to the ORDER BY list as shown in Listing 2-6 so that, in case of ties, the row with the greater order ID value will be preferred.orderid DESC添加到ORDER BY列表中,如Listing 2-6所示,以便在出现关系的情况下,优先选择订单ID值较大的行。
LISTING 2-6 Query demonstrating 演示TOP with unique ORDER BY listTOP配合唯一ORDER BY列表的查询
SELECT TOP (5) orderid, orderdate, custid, empid
FROM Sales.Orders
ORDER BY orderdate DESC, orderid DESC;
This query returns the following output:此查询返回以下输出:
orderid orderdate custid empid
----------- ---------- ----------- -----------
11077 2016-05-06 65 1
11076 2016-05-06 9 4
11075 2016-05-06 68 8
11074 2016-05-06 73 7
11073 2016-05-05 58 2
(5 row(s) affected)
If you examine the results of the queries from Listings 2-5 and 2-6, you'll notice that they seem to be the same. 如果检查Listing 2-5和Listing 2-6中的查询结果,您会发现它们似乎是相同的。The important difference is that the result shown in the query output for Listing 2-5 is one of several possible valid results for this query, whereas the result shown in the query output for Listing 2-6 is the only possible valid result.重要的区别在于,Listing 2-5的查询输出中显示的结果是该查询的几种可能有效结果之一,而Listing 2-6的查询输出中显示的结果是唯一可能有效的结果。
Instead of adding a tiebreaker to the 您可以请求返回所有不分胜负者,而不是向ORDER BY list, you can request to return all ties. ORDER BY列表中添加决胜器。For example, you can ask that, in addition to the five rows you get back from the query in Listing 2-5, all other rows from the table be returned that have the same sort value (order date, in this case) as the last one found (May 5, 2016, in this case). 例如,您可以要求,除了从Listing 2-5中的查询中返回的五行之外,还返回表中所有其他具有与上一行(本例中为2016年5月5日)相同排序值(本例中为订单日期)的行。You achieve this by adding the 您可以通过添加WITH TIES option, as shown in the following query:WITH TIES选项来实现这一点,如以下查询所示:
SELECT TOP (5) WITH TIES orderid, orderdate, custid, empid
FROM Sales.Orders
ORDER BY orderdate DESC;
This query returns the following output:此查询返回以下输出:
orderid orderdate custid empid
----------- ---------- ----------- -----------
11077 2016-05-06 65 1
11076 2016-05-06 9 4
11075 2016-05-06 68 8
11074 2016-05-06 73 7
11073 2016-05-05 58 2
11072 2016-05-05 20 4
11071 2016-05-05 46 1
11070 2016-05-05 44 2
(8 row(s) affected)
Notice that the output has eight rows, even though you specified 请注意,输出有8行,即使您指定了TOP (5). TOP (5)。SQL Server first returned the SQL Server首先根据TOP (5) rows based on orderdate DESC ordering, and it also returned all other rows from the table that had the same orderdate value as in the last of the five rows that were accessed. orderdate DESC排序返回前(5)行,还返回表中与被访问的五行中最后一行具有相同orderdate值的所有其他行。Using the WITH TIES option, the selection of rows is deterministic, but the presentation order among rows with the same order date isn't.使用WITH TIES选项,行的选择是确定的,但具有相同订单日期的行之间的显示顺序不是确定的。
OFFSET-FETCH filterOFFSET-FETCH筛选器The TOP filter is very practical, but it has two shortcomings—it's not standard, and it doesn't support a skipping capability. TOP筛选器非常实用,但它有两个缺点:它不是标准的,并且不支持跳过功能。T-SQL also supports a standard, T-SQL还支持一个名为TOP-like filter, called OFFSET-FETCH, which does support a skipping option. OFFSET-FETCH的标准类TOP筛选器,它确实支持跳过选项。This makes it very useful for ad-hoc paging purposes.这使得它对于临时分页非常有用。
The OFFSET-FETCH filter is considered an extension to the ORDER BY clause. OFFSET-FETCH筛选器被认为是ORDER BY子句的扩展。With the 使用OFFSET clause you indicate how many rows to skip, and with the FETCH clause you indicate how many rows to filter after the skipped rows. OFFSET子句可以指示要跳过多少行,使用FETCH子句可以指示在跳过的行之后要筛选多少行。As an example, consider the following query:作为一个例子,考虑下面的查询:
SELECT orderid, orderdate, custid, empid
FROM Sales.Orders
ORDER BY orderdate, orderid
OFFSET 50 ROWS FETCH NEXT 25 ROWS ONLY;
The query orders the rows from the 查询根据Orders table based on the orderdate and orderid attributes (from least recent to most recent, with orderid as the tiebreaker). orderdate和orderid属性(从最新到最新,以orderid作为分界线)对orders表中的行进行排序。Based on this ordering, the 基于这种排序,OFFSET clause skips the first 50 rows and the FETCH clause filters the next 25 rows only.OFFSET子句跳过前50行,FETCH子句只筛选接下来的25行。
Note that a query that uses 请注意,使用OFFSET-FETCH must have an ORDER BY clause. OFFSET-FETCH的查询必须具有ORDER BY子句。Also, T-SQL doesn't support the 此外,T-SQL不支持没有FETCH clause without the OFFSET clause. OFFSET子句的FETCH子句。If you do not want to skip any rows but do want to filter rows with the 如果不想跳过任何行,但想使用FETCH clause, you must indicate that by using OFFSET 0 ROWS. FETCH子句筛选行,则必须使用OFFSET 0 ROWS来指示。However, 但是,允许在不提取的情况下进行偏移。OFFSET without FETCH is allowed. In such a case, the query skips the indicated number of rows and returns all remaining rows in the result.在这种情况下,查询将跳过指定的行数,并返回结果中所有剩余的行。
There are interesting language aspects to note about the syntax for the 关于OFFSET-FETCH filter. OFFSET-FETCH筛选器的语法,有一些有趣的语言方面需要注意。The singular and plural forms 单数和复数形式ROW and ROWS are interchangeable. ROW和ROWS可以互换。The idea behind this is to allow you to phrase the filter in an intuitive English-like manner. 这背后的想法是让你能够以一种直观的英语方式表达筛选器。For example, suppose you want to fetch only one row; though it would be syntactically valid, it would nevertheless look strange if you specified 例如,假设您只想获取一行;虽然它在语法上是有效的,但如果指定FETCH 1 ROWS. FETCH 1 ROWS,它看起来会很奇怪。Therefore, you're allowed to use the form 因此,您可以使用形式FETCH 1 ROW. FETCH 1 ROW。The same principle applies to the 同样的原则也适用于OFFSET clause. OFFSET子句。Also, if you're not skipping any rows (此外,如果不跳过任何行(OFFSET 0 ROWS), you might find the term “first” more suitable than “next.” OFFSET 0 ROWS),您可能会发现术语“first”比“next”更合适。Hence, the forms 因此,FIRST and NEXT are interchangeable.FIRST和NEXT两种形式是可互换的。
As you can see, the 正如您所见,OFFSET-FETCH filter is more flexible than the TOP filter in the sense that it supports a skipping capability. OFFSET-FETCH筛选器比TOP筛选器更灵活,因为它支持跳过功能。However, at the date of this writing (the year 2016), the T-SQL implementation of the 然而,在本文撰写之日(2016年),OFFSET-FETCH filter doesn't yet support the PERCENT and WITH TIES options that TOP does. OFFSET-FETCH筛选器的T-SQL实现还不支持TOP所支持的百分比和WITH TIES选项。Curiously, the SQL standard specification for the 奇怪的是,OFFSET-FETCH filter does support these options.OFFSET-FETCH筛选器的SQL标准规范确实支持这些选项。
A window function is a function that, for each row in the underlying query, operates on a window (set) of rows that is derived from the underlying query result, and computes a scalar (single) result value. 窗口函数是一个函数,对于基础查询中的每一行,它对从基础查询结果派生的一个窗口(集合)行进行操作,并计算一个标量(单个)结果值。The window of rows is defined with an 行窗口由OVER clause. OVER子句定义。Window functions are profound; you can use them to address a wide variety of needs, such as to perform data-analysis calculations. 窗口功能深刻;您可以使用它们来满足各种各样的需求,例如执行数据分析计算。T-SQL supports several categories of window functions, and each category has several functions. T-SQL支持多个类别的窗口函数,每个类别都有多个函数。Window functions are a SQL standard, but T-SQL supports a subset of the features from the standard.窗口函数是SQL标准,但T-SQL支持该标准中的一部分功能。
At this point in the book, it could be premature to get into too much detail. 在这本书的这个阶段,谈论太多细节可能还为时过早。For now, I'll just provide a glimpse into the concept and demonstrate it by using the 现在,我将简要介绍这个概念,并通过使用ROW_NUMBER window function. ROW_NUMBER窗口函数来演示它。Later in the book (in Chapter 7, “Beyond the fundamentals of querying”), I provide more details.在本书的后面部分(第7章,“超越查询的基本原理”),我提供了更多细节。
As mentioned, a window function operates on a set of rows exposed to it by the 如前所述,窗口函数对OVER clause. OVER子句暴露给它的一组行进行操作。For each row in the underlying query, the 对于基础查询中的每一行,OVER clause exposes to the function a subset of the rows from the underlying query's result set. OVER子句向函数公开基础查询结果集中的行的子集。The OVER clause can restrict the rows in the window by using a window partition subclause (PARTITION BY). OVER子句可以通过使用窗口分区子句(PARTITION BY)来限制窗口中的行。It can define ordering for the calculation (if relevant) using a window order subclause (它可以使用窗口排序子句(ORDER BY)—not to be confused with the query's presentation ORDER BY clause.ORDER BY)定义计算的顺序(如果相关的话)——不要与查询的演示ORDER BY子句混淆。
Consider the following query as an example:把下面的查询作为一个例子:
SELECT orderid, custid, val,
ROW_NUMBER() OVER(PARTITION BY custid
ORDER BY val) AS rownum
FROM Sales.OrderValues
ORDER BY custid, val;
This query generates the following output:此查询生成以下输出:
orderid custid val rownum
----------- ----------- --------------------------------------- --------------------
10702 1 330.00 1
10952 1 471.20 2
10643 1 814.50 3
10835 1 845.80 4
10692 1 878.00 5
11011 1 933.50 6
10308 2 88.80 1
10759 2 320.00 2
10625 2 479.75 3
10926 2 514.40 4
10682 3 375.50 1
...
(830 row(s) affected)
The ROW_NUMBER function assigns unique, sequential, incrementing integers to the rows in the result within the respective partition, based on the indicated ordering. ROW_NUMBER函数根据指定的顺序,为相应分区内结果中的行分配唯一、连续、递增的整数。The 这个示例函数中的OVER clause in this example function partitions the window by the custid attribute; hence, the row numbers are unique to each customer. OVER子句通过custid属性划分窗口;因此,每个客户的行号都是唯一的。The OVER clause also defines ordering in the window by the val attribute, so the sequential row numbers are incremented within the partition based on the values in this attribute.OVER子句还通过val属性定义窗口中的顺序,因此分区内的连续行号将根据该属性中的值递增。
Note that the 请注意,ROW_NUMBER function must produce unique values within each partition. ROW_NUMBER函数必须在每个分区内生成唯一的值。This means that even when the ordering value doesn't increase, the row number still must increase. 这意味着,即使排序值没有增加,行号也必须增加。Therefore, if the 因此,如果ROW_NUMBER function's ORDER BY list is non-unique, as in the preceding example, the query is nondeterministic. ROW_NUMBER函数的ORDER BY列表是非唯一的,如上例所示,则查询是不确定的。That is, more than one correct result is possible. 也就是说,可能有不止一个正确的结果。If you want to make a row number calculation deterministic, you must add elements to the 如果要使行号计算具有确定性,必须将元素添加到ORDER BY list to make it unique. ORDER BY列表中以使其唯一。For example, in our sample query you can achieve this by adding the 例如,在示例查询中,您可以通过添加orderid attribute as a tiebreaker.orderid属性作为一个决胜器来实现这一点。
Window ordering should not be confused with presentation ordering; it does not prevent the result from being relational. 窗口排序不应与演示文稿排序混淆;这并不妨碍结果的关联性。Also, specifying window ordering in a window function doesn't give you any presentation-ordering guarantees. 此外,在窗口函数中指定窗口顺序并不能保证演示文稿的顺序。If you need to guarantee presentation ordering, you must add a presentation 如果需要保证演示文稿的顺序,必须添加一个演示ORDER BY clause, as I did in the last query.ORDER BY子句,就像我在上一个查询中所做的那样。
Note that expressions in the 请注意,SELECT list are evaluated before the DISTINCT clause (if one exists). SELECT列表中的表达式在DISTINCT子句(如果存在)之前求值。This rule also applies to expressions based on window functions that appear in the 此规则也适用于基于SELECT list. SELECT列表中显示的窗口函数的表达式。I explain the significance of this fact in Chapter 7.我在第7章中解释了这一事实的意义。
To put it all together, the following list presents the logical order in which all clauses discussed so far are processed:下面列出了迄今为止讨论的所有子句的处理逻辑顺序:
FROM
WHERE
GROUP BY
HAVING
SELECT
• Expressions
• DISTINCT
ORDER BY
• TOP/OFFSET-FETCH
T-SQL has language elements in which predicates can be specified—for example, query filters such as T-SQL有一些语言元素,可以在其中指定谓词,例如,查询筛选器,如WHERE and HAVING, CHECK constraints, and others. WHERE和HAVING、CHECK约束等。Remember that predicates are logical expressions that evaluate to 请记住,谓词是计算结果为TRUE, FALSE, or UNKNOWN. TRUE、FALSE或UNKNOWN的逻辑表达式。You can combine predicates by using logical operators such as 可以使用逻辑运算符组合谓词,例如AND (forming a combination known as a conjunction of predicates) and OR (known as a disjunction of predicates). AND(形成称为谓词连接的组合)和OR(称为谓词析取)。You can also involve other types of operators, such as comparison operators, in your expressions.表达式中还可以包含其他类型的运算符,例如比较运算符。
Examples of predicates supported by T-SQL include T-SQL支持的谓词示例包括IN, BETWEEN, and LIKE. IN、BETWEEN和LIKE。You use the 使用IN predicate to check whether a value, or scalar expression, is equal to at least one of the elements in a set. IN谓词检查值或标量表达式是否至少等于集合中的一个元素。For example, the following query returns orders in which the order ID is equal to 10248, 10249, or 10250:例如,以下查询返回订单ID等于10248、10249或10250的订单:
SELECT orderid, empid, orderdate
FROM Sales.Orders
WHERE orderid IN(10248, 10249, 10250);
You use the 使用BETWEEN predicate to check whether a value is in a specified range, inclusive of the two specified delimiters. BETWEEN谓词检查值是否在指定范围内,包括两个指定的分隔符。For example, the following query returns all orders in the inclusive range 10300 through 10310:例如,以下查询返回10300到10310范围内的所有订单:
SELECT orderid, empid, orderdate
FROM Sales.Orders
WHERE orderid BETWEEN 10300 AND 10310;
With the 使用LIKE predicate, you can check whether a character string value meets a specified pattern. LIKE谓词,可以检查字符串值是否符合指定的模式。For example, the following query returns employees whose last names start with the letter 例如,以下查询返回姓氏以字母D:D开头的员工:
SELECT empid, firstname, lastname
FROM HR.Employees
WHERE lastname LIKE N'D%';
Later in this chapter, I'll elaborate on pattern matching and the 在本章后面,我将详细介绍模式匹配和LIKE predicate.LIKE谓词。
Notice the use of the letter 注意使用字母N to prefix the string 'D%'; it stands for National and is used to denote that a character string is of a Unicode data type (NCHAR or NVARCHAR), as opposed to a regular character data type (CHAR or VARCHAR). N作为字符串'D%'的前缀;它代表自然,用于表示字符串是Unicode数据类型(NCHAR或NVARCHAR),而不是常规字符数据类型(CHAR或VARCHAR)。Because the data type of the 因为lastname attribute is NVARCHAR(40), the letter N is used to prefix the string. lastname属性的数据类型是NVARCHAR(40),所以字母N被用来作为字符串的前缀。Later in this chapter, in the section “Working with character data,” I elaborate on the treatment of character strings.在本章后面的“处理字符数据”一节中,我将详细介绍字符串的处理。
T-SQL supports the following comparison operators: =, >, <, >=, <=, <>, !=, !>, !<, of which the last three are not standard. T-SQL支持以下比较运算符:=,>,<,>=,<=,<=,<>,!=,!>,!<,其中最后三个不是标准的。Because the nonstandard operators have standard alternatives (such as <> instead of !=), I recommend you avoid using nonstandard operators. 因为非标准运算符有标准的替代选项(例如<>而不是!=),我建议您避免使用非标准运算符。For example, the following query returns all orders placed on or after January 1, 2016:例如,以下查询返回2016年1月1日当天或之后的所有订单:
SELECT orderid, empid, orderdate
FROM Sales.Orders
WHERE orderdate >= '20160101';
If you need to combine logical expressions, you can use the logical operators 如果需要组合逻辑表达式,可以使用逻辑运算符OR and AND. OR和AND。If you want to negate an expression, you can use the 如果要对表达式求否,可以使用NOT operator. NOT运算符。For example, the following query returns orders placed on or after January 1, 2016, that were handled by one of the employees whose ID is 1, 3, or 5:例如,以下查询返回2016年1月1日当天或之后的订单,这些订单由ID为1、3或5的员工之一处理:
SELECT orderid, empid, orderdate
FROM Sales.Orders
WHERE orderdate >= '20160101'
AND empid IN(1, 3, 5);
T-SQL supports the four obvious arithmetic operators: +, –, *, and /. T-SQL支持四个明显的算术运算符:+、-、*和/。It also supports the % operator (modulo), which returns the remainder of integer division. 它还支持%运算符(求模),它返回整数除法的余数。For example, the following query calculates the net value as a result of arithmetic manipulation of the 例如,以下查询计算quantity, unitprice, and discount attributes:quantity(数量)、unitprice(单价)和discount(折扣)属性算术运算后的净值:
SELECT orderid, productid, qty, unitprice, discount,
qty * unitprice * (1 - discount) AS val
FROM Sales.OrderDetails;
Note that the data type of a scalar expression involving two operands is determined in T-SQL by the higher of the two in terms of data-type precedence. 请注意,涉及两个操作数的标量表达式的数据类型在T-SQL中由两个操作数中的较高者根据数据类型优先级确定。If both operands are of the same data type, the result of the expression is of the same data type as well. 如果两个操作数的数据类型相同,则表达式的结果也具有相同的数据类型。For example, a division between two integers (例如,两个整数(INT) yields an integer. INT)之间的除法产生一个整数。The expression 5/2 returns the integer 2 and not the numeric 2.5. 表达式5/2返回整数2,而不是数字2.5。This is not a problem when you are dealing with constants, because you can always specify the values as numeric ones with a decimal point. 在处理常量时,这不是问题,因为可以始终将值指定为带小数点的数字。But when you are dealing with, say, two integer columns, as in 但是,当处理两个整数列时,例如在col1/col2, you need to cast the operands to the appropriate type if you want the calculation to be a numeric one: CAST(col1 AS NUMERIC(12, 2))/CAST(col2 AS NUMERIC(12, 2)). col1/col2中,如果希望计算是数值的,则需要将操作数转换为适当的类型:CAST(col1 AS NUMERIC(12, 2))/CAST(col2 AS NUMERIC(12, 2))。The data type 数据类型NUMERIC(12, 2) has a precision of 12 and a scale of 2, meaning that it has 12 digits in total, 2 of which are after the decimal point.NUMERIC(12, 2)的精度为12,刻度为2,这意味着它总共有12位数字,其中2位位于小数点之后。
If the two operands are of different types, the one with the lower precedence is promoted to the one that is higher. 如果两个操作数的类型不同,则优先级较低的操作数将升级为优先级较高的操作数。For example, in the expression 5/2.0, the first operand is 例如,在表达式5/2.0中,第一个操作数是INT and the second is NUMERIC. INT,第二个是NUMERIC。Because 因为NUMERIC is considered higher than INT, the INT operand 5 is implicitly converted to the NUMERIC 5.0 before the arithmetic operation, and you get the result 2.5.NUMERIC被认为高于INT,所以在进行算术运算之前,INT操作数5会隐式转换为NUMERIC 5.0,得到结果2.5。
You can find the precedence order among types in SQL Server Books Online under “Data Type Precedence.”您可以在SQL Server联机丛书的“数据类型优先”下找到类型之间的优先顺序。
When multiple operators appear in the same expression, SQL Server evaluates them based on operator precedence rules. 当多个运算符出现在同一个表达式中时,SQL Server会根据运算符优先级规则对其求值。The following list describes the precedence among operators, from highest to lowest:以下列表描述了运算符之间的优先级,从最高到最低:
1. ( ) (Parentheses)(圆括号)
2. * (Multiplication), (乘法)、/ (Division), (除法)% (Modulo)(求模)
3. + (Positive), – (Negative), + (Addition), + (Concatenation), – (Subtraction)+(正),-(负),+(加法),+(串联),-(减法)
4. =, >, <, >=, <=, <>, !=, !>, !< (Comparison operators)=、>、<、>=、<=、<>、!=、!>、!< (比较运算符)
5. NOT
6. AND
7. BETWEEN, IN, LIKE, ORBETWEEB、IN、LIKE
8. = (Assignment)(赋值)
For example, in the following query, 例如,在以下查询中,AND has precedence over OR:AND优先于OR:
SELECT orderid, custid, empid, orderdate
FROM Sales.Orders
WHERE
custid = 1
AND empid IN(1, 3, 5)
OR custid = 85
AND empid IN(2, 4, 6);
The query returns orders that were either “placed by customer 1 and handled by employees 1, 3, or 5” or “placed by customer 85 and handled by employees 2, 4, or 6.”该查询返回“由客户1下单并由员工1、3或5处理”或“由客户85下单并由员工2、4或6处理”的订单
Parentheses have the highest precedence, so they give you full control. 括号的优先级最高,因此可以完全控制。For the sake of other people who need to review or maintain your code and for readability purposes, it's a good practice to use parentheses even when they are not required. 为了其他需要检查或维护代码的人,以及为了可读性的目的,使用括号是一种很好的做法,即使括号不是必需的。The same is true with indentation. 缩进也是如此。For example, the following query is the logical equivalent of the previous query, only its logic is much clearer:例如,下面的查询与前面的查询在逻辑上是等价的,只是它的逻辑要清晰得多:
SELECT orderid, custid, empid, orderdate
FROM Sales.Orders
WHERE
(custid = 1
AND empid IN(1, 3, 5))
OR
(custid = 85
AND empid IN(2, 4, 6));
Using parentheses to force precedence with logical operators is similar to using parentheses with arithmetic operators. 使用括号强制逻辑运算符优先与使用算术运算符的括号类似。For example, without parentheses in the following expression, multiplication precedes addition:例如,在下列表达式中,如果没有括号,则乘法先于加法:
SELECT 10 + 2 * 3;
Therefore, this expression returns 16. 因此,这个表达式返回16。You can use parentheses to force the addition to be calculated first:可以使用括号强制首先计算加法:
SELECT (10 + 2) * 3;
This time, the expression returns 36.这一次,表达式返回36。
CASE expressionsCASE表达式A CASE expression is a scalar expression that returns a value based on conditional logic. CASE表达式是基于条件逻辑返回值的标量表达式。It is based on the SQL standard. 它基于SQL标准。Note that 注意,CASE is an expression and not a statement; that is, it doesn't take action such as controlling the flow of your code. CASE是一个表达式,而不是一个语句;也就是说,它不会采取诸如控制代码流之类的操作。Instead, it returns a value. 相反,它返回一个值。Because 因为CASE is a scalar expression, it is allowed wherever scalar expressions are allowed, such as in the SELECT, WHERE, HAVING, and ORDER BY clauses and in CHECK constraints.CASE是一个标量表达式,所以在允许标量表达式的任何地方都可以使用CASE,例如在SELECT、WHERE、HAVING和ORDER BY子句以及CHECK约束中。
There are two forms of CASE expressions: simple and searched. CASE表达式有两种形式:simple和searched。You use the simple form to compare one value or scalar expression with a list of possible values and return a value for the first match. 您可以使用简单的表单将一个值或标量表达式与可能的值列表进行比较,并返回第一个匹配的值。If no value in the list is equal to the tested value, the 如果列表中没有与测试值相等的值,则CASE expression returns the value that appears in the ELSE clause (if one exists). CASE表达式返回ELSE子句中出现的值(如果存在)。If the 如果CASE expression doesn't have an ELSE clause, it defaults to ELSE NULL.CASE表达式没有ELSE子句,则默认为ELSE NULL。
For example, the following query against the 例如,以下针对Production.Products table uses a CASE expression in the SELECT clause to produce the description of the categoryid column value:Production.Products表的查询使用SELECT子句中的CASE表达式来生成categoryname列值的描述:
SELECT productid, productname, categoryid,
CASE categoryid
WHEN 1 THEN 'Beverages'
WHEN 2 THEN 'Condiments'
WHEN 3 THEN 'Confections'
WHEN 4 THEN 'Dairy Products'
WHEN 5 THEN 'Grains/Cereals'
WHEN 6 THEN 'Meat/Poultry'
WHEN 7 THEN 'Produce'
WHEN 8 THEN 'Seafood'
ELSE 'Unknown Category'
END AS categoryname
FROM Production.Products;
This query produces the following output, shown in abbreviated form:此查询生成以下输出,以缩写形式显示:
productid productname categoryid categoryname
----------- -------------- ----------- ----------------
1 Product HHYDP 1 Beverages
2 Product RECZE 1 Beverages
3 Product IMEHJ 2 Condiments
4 Product KSBRM 2 Condiments
5 Product EPEIM 2 Condiments
6 Product VAIIV 2 Condiments
7 Product HMLNI 7 Produce
8 Product WVJFP 2 Condiments
9 Product AOZBW 6 Meat/Poultry
10 Product YHXGE 8 Seafood
...
(77 row(s) affected)
Note that this query is used for illustration purposes. 请注意,此查询用于说明目的。Normally you maintain the product categories in a table and join that table with the 通常,您会在一个表中维护产品类别,并在需要获取类别描述时将该表与Products table when you need to get the category descriptions. Products表连接起来。In fact, the 实际上,TSQLV4 database has just such a Categories table.TSQLV4数据库就是这样一个Categories表。
The simple 简单CASE form has a single test value or expression right after the CASE keyword that is compared with a list of possible values in the WHEN clauses. CASE表单在CASE关键字后面有一个测试值或表达式,与WHEN子句中可能的值列表进行比较。The searched 搜索的CASE form is more flexible in the sense you can specify predicates in the WHEN clauses rather than being restricted to using equality comparisons. CASE形式更灵活,因为您可以在WHEN子句中指定谓词,而不限于使用相等比较。The searched 搜索的CASE expression returns the value in the THEN clause that is associated with the first WHEN predicate that evaluates to TRUE. CASE表达式返回THEN子句中的值,该值与计算结果为TRUE的第一个WHEN谓词关联。If none of the 如果WHEN predicates evaluates to TRUE, the CASE expression returns the value that appears in the ELSE clause (or NULL if an ELSE clause is not present). WHEN谓词没有一个计算为TRUE,则CASE表达式返回出现在ELSE子句中的值(如果没有ELSE子句出现则返回NULL)。For example, the following query produces a value category description based on whether the value is less than 1,000.00, between 1,000.00 and 3,000.00, or greater than 3,000.00:例如,以下查询根据值是小于1000.00、介于1000.00和3000.00之间还是大于3000.00生成值类别描述:
SELECT orderid, custid, val,
CASE
WHEN val < 1000.00 THEN 'Less than 1000'
WHEN val BETWEEN 1000.00 AND 3000.00 THEN 'Between 1000 and 3000'
WHEN val > 3000.00 THEN 'More than 3000'
ELSE 'Unknown'
END AS valuecategory
FROM Sales.OrderValues;
This query generates the following output:此查询生成以下输出:
orderid custid val valuecategory
----------- ----------- -------- ---------------------
10248 85 440.00 Less than 1000
10249 79 1863.40 Between 1000 and 3000
10250 34 1552.60 Between 1000 and 3000
10251 84 654.06 Less than 1000
10252 76 3597.90 More than 3000
10253 34 1444.80 Between 1000 and 3000
10254 14 556.62 Less than 1000
10255 68 2490.50 Between 1000 and 3000
10256 88 517.80 Less than 1000
10257 35 1119.90 Between 1000 and 3000
...
(830 row(s) affected)
You can see that every simple 您可以看到,每个简单的CASE expression can be converted to the searched CASE form, but the reverse is not true.CASE表达式都可以转换为搜索的CASE形式,但反过来却不是。
T-SQL supports some functions you can consider as abbreviations of the T-SQL支持一些可以被看作是CASE expression: ISNULL, COALESCE, IIF, and CHOOSE. CASE表达式缩写的函数:ISNULL、COALESCE、IIF和CHOOSE。Note that of the four, only 请注意,在这四种方法中,只有COALESCE is standard.COALESCE是标准的。
The ISNULL function accepts two arguments as input and returns the first that is not NULL, or NULL if both are NULL. ISNULL函数接受两个参数作为输入,并返回第一个不为NULL的参数,如果两者都为NULL,则返回NULL。For example 例如,ISNULL(col1, '') returns the col1 value if it isn't NULL and an empty string if it is NULL. ISNULL(col1, '')如果不为NULL,则返回col1值,如果为NULL,则返回空字符串。The COALESCE function is similar, only it supports two or more arguments and returns the first that isn't NULL, or NULL if all are NULL.COALESCE函数类似,只是它支持两个或多个参数,并返回第一个非NULL的参数,如果所有参数都为NULL,则返回NULL。
See Also另见
It's a common question whether you should use ISNULL or COALESCE. ISNULL还是COALESCE是一个常见的问题。I cover the topic in detail in my SQL Server Pro magazine column in the following article: .。
The nonstandard T-SQL中添加了非标准的IIF and CHOOSE functions were added to T-SQL to support easier migrations from Microsoft Access. IIF和CHOOSE函数,以支持从Microsoft Access进行更轻松的迁移。The function 如果IIF(<logical_expression>, <expr1>, <expr2>) returns expr1 if logical_expression is TRUE, and it returns expr2 otherwise. logical_expression为TRUE,则函数IIF(<logical_expression>, <expr1>, <expr2>)返回expr1,否则返回expr2。For example, the expression 例如,如果IIF(col1 <> 0, col2/col1, NULL) returns the result of col2/col1 if col1 is not zero; otherwise, it returns a NULL. col1不为零,表达式IIF(col1 <> 0, col2/col1, NULL)返回col2/col1的结果;否则,它将返回NULL。The function 函数CHOOSE(<index>, <expr1>, <expr2>, ..., <exprn>) returns the expression from the list in the specified index. CHOOSE(<index>, <expr1>, <expr2>, ..., <exprn>)从指定索引的列表中返回表达式。For example, the expression 例如,表达式CHOOSE(3, col1, col2, col3) returns the value of col3. CHOOSE(3, col1, col2, col3)返回col3的值。Of course, actual expressions that use the 当然,使用CHOOSE function tend to be more dynamic—for example, relying on user input.CHOOSE函数的实际表达式往往更具动态性,例如,依赖于用户输入。
So far, I've just used a few examples to familiarize you with the 到目前为止,我只使用了几个例子来熟悉CASE expression and related functions. CASE表达式和相关函数。Even though it might not be apparent at this point from these examples, the 尽管从这些例子中可能看不出这一点,但CASE expression is an extremely powerful and useful language element.CASE表达式是一个非常强大和有用的语言元素。
NULLsNULLAs explained in Chapter 1, “Background to T-SQL querying and programming,” SQL supports the 正如第1章“T-SQL查询和编程的背景”中所解释的,SQL支持空标记来表示缺失的值,并使用三值谓词逻辑,这意味着谓词可以计算为NULL marker to represent missing values and uses three-valued predicate logic, meaning that predicates can evaluate to TRUE, FALSE, or UNKNOWN. TRUE、FALSE或UNKNOWN。T-SQL follows the standard in this respect. T-SQL在这方面遵循标准。Treatment of SQL中对NULLs and UNKNOWN in SQL can be confusing because intuitively people are more accustomed to thinking in terms of two-valued logic (TRUE and FALSE). NULL和UNKNOWN的处理可能会令人困惑,因为直觉上人们更习惯于用两值逻辑(TRUE和FALSE)来思考。To add to the confusion, different language elements in SQL treat 更令人困惑的是,SQL中的不同语言元素不一致地处理NULLs and UNKNOWN inconsistently.NULL和UNKNOWN。
Let's start with three-valued predicate logic. 让我们从三值谓词逻辑开始。A logical expression involving only non-仅涉及非NULL values evaluates to either TRUE or FALSE. NULL值的逻辑表达式的计算结果为TRUE或FALSE。When the logical expression involves a missing value, it evaluates to 当逻辑表达式包含缺少的值时,其计算结果为UNKNOWN. UNKNOWN。For example, consider the predicate 例如,考虑谓词salary > 0. salary > 0。When 当salary is equal to 1,000, the expression evaluates to TRUE. salary等于1000时,表达式的计算结果为TRUE。When 当salary is equal to –1,000, the expression evaluates to FALSE. salary等于-1000时,表达式的计算结果为FALSE。When 当salary is NULL, the expression evaluates to UNKNOWN.salary为NULL时,表达式的计算结果为UNKNOWN。
SQL treats SQL以直观且可能是预期的方式处理TRUE and FALSE in an intuitive and probably expected manner. TRUE与FALSE。For example, if the predicate 例如,如果谓词salary > 0 appears in a query filter (such as in a WHERE or HAVING clause), rows or groups for which the expression evaluates to TRUE are returned, whereas those for which the expression evaluates to FALSE are discarded. salary>0出现在查询筛选器中(例如WHERE或HAVING子句中),则返回表达式计算结果为TRUE的行或组,而丢弃表达式计算结果为FALSE的行或组。Similarly, if the predicate 类似地,如果谓词salary > 0 appears in a CHECK constraint in a table, INSERT or UPDATE statements for which the expression evaluates to TRUE for all rows are accepted, whereas those for which the expression evaluates to FALSE for any row are rejected.salary>0出现在表中的CHECK约束中,则接受表达式对所有行的计算结果为TRUE的INSERT或UPDATE语句,而对任何行的计算结果为FALSE的INSERT或UPDATE语句将被拒绝。
SQL has different treatments for SQL对不同语言元素中的UNKNOWN in different language elements (and for some people, not necessarily the expected treatments). UNKNOWN有不同的处理方法(对某些人来说,不一定是预期的处理方法)。The treatment SQL has for query filters is “accept SQL对查询筛选器的处理方式是“接受TRUE,” meaning that both FALSE and UNKNOWN are discarded. TRUE”,这意味着FALSE和UNKNOWN都将被丢弃。Conversely, the definition of the treatment SQL has for 相反,SQL对检查约束的处理定义为“拒绝CHECK constraints is “reject FALSE,” meaning that both TRUE and UNKNOWN are accepted. FALSE”,这意味着接受TRUE和UNKNOWN。Had SQL used two-valued predicate logic, there wouldn't have been a difference between the definitions “accept 如果SQL使用两值谓词逻辑,那么“接受TRUE” and “reject FALSE.” TRUE”和“拒绝FALSE”的定义就不会有区别。But with three-valued predicate logic, “accept 但对于三值谓词逻辑,“接受TRUE” rejects UNKNOWN, whereas “reject FALSE” accepts it. TRUE”拒绝UNKNOWN,而“拒绝FALSE”接受UNKNOWN。With the predicate 对于上一个示例中的谓词salary > 0 from the previous example, a NULL salary would cause the expression to evaluate to UNKNOWN. salary>0,NULL薪资将导致表达式的计算结果为UNKNOWN。If this predicate appears in a query's 如果此谓词出现在查询的WHERE clause, a row with a NULL salary will be discarded. WHERE子句中,则将丢弃薪资为NULL的行。If this predicate appears in a 如果该谓词出现在表中的CHECK constraint in a table, a row with a NULL salary will be accepted.CHECK约束中,则接受薪资为NULL的行。
One of the tricky aspects of the logical value 逻辑值UNKNOWN is that when you negate it, you still get UNKNOWN. UNKNOWN的一个棘手方面是,当你否定它时,你仍然得到UNKNOWN。For example, given the predicate 例如,给定谓词NOT (salary > 0), when salary is NULL, salary > 0 evaluates to UNKNOWN, and NOT UNKNOWN remains UNKNOWN.NOT (salary > 0),当salary为NULL时,salary>0的计算结果为UNKNOWN,而NOT UNKNOWN仍为UNKNOWN。
What some people find surprising is that an expression comparing two 有些人感到惊讶的是,一个比较两个NULLs (NULL = NULL) evaluates to UNKNOWN. NULL(NULL=NULL)的表达式的计算结果是UNKNOWN。The reasoning for this from SQL's perspective is that a 从SQL的角度来看,这种情况的原因是NULL represents a missing value, and you can't really tell whether one missing value is equal to another. NULL代表缺少的值,并且您无法真正判断缺少的值是否等于另一个。Therefore, SQL provides you with the predicates 因此,SQL为您提供了谓词IS NULL and IS NOT NULL, which you should use instead of = NULL and <> NULL.IS NULL和IS NOT NULL,您应该使用它们来代替=NULL和<>NULL。
To make things a bit more tangible, I'll demonstrate the ramifications of three-valued logic with an example. 为了让事情更具体一些,我将用一个例子演示三值逻辑的后果。The Sales.Customers table has three attributes, called country, region, and city, where the customer's location information is stored. Sales.Customers表有三个属性,称为country、region和city,用于存储客户的位置信息。All locations have existing countries and cities. 所有地点都有现有的国家和城市。Some have existing regions (such as 一些地区已经存在(例如country: USA, region: WA, city: Seattle), yet for some the region element is missing but inapplicable (such as country: UK, region: NULL, city: London). country:美国、region:WA、city:西雅图),但对于一些地区,地区元素缺失但不适用(例如country:英国、region:NULL、city:伦敦)。Consider the following query, which attempts to return all customers where the region is equal to WA:考虑下面的查询,该查询试图返回区域等于WA的所有客户:
SELECT custid, country, region, city
FROM Sales.Customers
WHERE region = N'WA';
This query generates the following output:此查询生成以下输出:
custid country region city
----------- --------------- --------------- ---------------
43 USA WA Walla Walla
82 USA WA Kirkland
89 USA WA Seattle
Out of the 91 rows in the 在Customers table, the query returns the three rows where the region attribute is equal to WA. Customers表中的91行中,查询返回region属性等于WA的三行。The query returns neither rows in which the value in the 查询既不返回region attribute is present and different than WA (the predicate evaluates to FALSE) nor those where the region attribute is NULL (the predicate evaluates to UNKNOWN). region属性中的值存在且不同于WA(谓词的计算结果为FALSE)的行,也不返回区域属性为NULL(谓词的计算结果为未知)的行。Most people would consider this result as the expected one.大多数人都认为这个结果是预期的结果。
The following query attempts to return all customers for whom the region is different than WA:以下查询试图返回区域与WA不同的所有客户:
SELECT custid, country, region, city
FROM Sales.Customers
WHERE region <> N'WA';
This query generates the following output:此查询生成以下输出:
custid country region city
----------- --------------- --------------- ---------------
10 Canada BC Tsawassen
15 Brazil SP Sao Paulo
21 Brazil SP Sao Paulo
31 Brazil SP Campinas
32 USA OR Eugene
33 Venezuela DF Caracas
34 Brazil RJ Rio de Janeiro
35 Venezuela Táchira San Cristóbal
36 USA OR Elgin
37 Ireland Co. Cork Cork
38 UK Isle of Wight Cowes
42 Canada BC Vancouver
45 USA CA San Francisco
46 Venezuela Lara Barquisimeto
47 Venezuela Nueva Esparta I. de Margarita
48 USA OR Portland
51 Canada Québec Montréal
55 USA AK Anchorage
61 Brazil RJ Rio de Janeiro
62 Brazil SP Sao Paulo
65 USA NM Albuquerque
67 Brazil RJ Rio de Janeiro
71 USA ID Boise
75 USA WY Lander
77 USA OR Portland
78 USA MT Butte
81 Brazil SP Sao Paulo
88 Brazil SP Resende
(28 row(s) affected)
If you expected to get 88 rows back (91 rows in the table minus 3 returned by the previous query), you might find this result (with just 28 rows) surprising. 如果您希望返回88行(表中的91行减去上一个查询返回的3行),那么您可能会发现这个结果(只有28行)令人惊讶。But remember, a query filter “accepts 但请记住,查询筛选器“接受TRUE,” meaning that it rejects both FALSE and UNKNOWN. TRUE”,这意味着它同时拒绝FALSE和UNKNOWN。So this query returned rows in which the 因此,这个查询返回了region value was present and different than WA. region值存在且与WA不同的行。It returned neither rows in which the 它既不返回region value was equal to WA nor rows in which region was NULL. region值等于WA的行,也不返回region值为NULL的行。You will get the same output if you use the predicate 如果使用谓词NOT (region = N'WA'). NOT (region = N'WA'),将得到相同的输出。That's because in the rows where 这是因为在region is NULL the expression region = N'WA' evaluates to UNKNOWN, and NOT (region = N'WA') evaluates to UNKNOWN also.region为NULL的行中,表达式region=N'WA'的计算结果为UNKNOWN,而NOT (region = N'WA')的计算结果也为UNKNOWN。
If you want to return all rows for which 如果要返回region is NULL, do not use the predicate region = NULL, because the expression evaluates to UNKNOWN in all rows—both those in which the value is present and those in which the value is missing (is NULL). region为NULL的所有行,请不要使用谓词region=NULL,因为表达式在所有行中的计算结果都是UNKNOWN,包括存在值的行和缺少值的行(为NULL)。The following query returns an empty set:以下查询返回一个空集:
SELECT custid, country, region, city
FROM Sales.Customers
WHERE region = NULL;
custid country region city
----------- --------------- --------------- ---------------
(0 row(s) affected)
Instead, you should use the 相反,您应该使用IS NULL predicate:IS NULL谓词:
SELECT custid, country, region, city
FROM Sales.Customers
WHERE region IS NULL;
This query generates the following output, shown in abbreviated form:此查询生成以下输出,以缩写形式显示:
custid country region city
----------- --------------- --------------- ---------------
1 Germany NULL Berlin
2 Mexico NULL México D.F.
3 Mexico NULL México D.F.
4 UK NULL London
5 Sweden NULL Luleå
6 Germany NULL Mannheim
7 France NULL Strasbourg
8 Spain NULL Madrid
9 France NULL Marseille
11 UK NULL London
...
(60 row(s) affected)
If you want to return all rows for which the 如果要返回region attribute is different than WA, including those in which the value is missing, you need to include an explicit test for NULLs, like this:region属性与WA不同的所有行,包括缺少值的行,则需要包含一个明确的NULL值测试,如下所示:
SELECT custid, country, region, city
FROM Sales.Customers
WHERE region <> N'WA'
OR region IS NULL;
This query generates the following output, shown in abbreviated form:此查询生成以下输出,以缩写形式显示:
custid country region city
----------- --------------- --------------- ---------------
1 Germany NULL Berlin
2 Mexico NULL México D.F.
3 Mexico NULL México D.F.
4 UK NULL London
5 Sweden NULL Luleå
6 Germany NULL Mannheim
7 France NULL Strasbourg
8 Spain NULL Madrid
9 France NULL Marseille
10 Canada BC Tsawassen
...
(88 row(s) affected)
SQL also treats 为了进行比较和排序,SQL还在不同的语言元素中不一致地处理NULLs inconsistently in different language elements for comparison and sorting purposes. NULL值。Some elements treat two 有些元素将两个NULLs as equal to each other, and others treat them as different.NULL值视为彼此相等,而另一些元素将它们视为不同。
For example, for grouping and sorting purposes, two 例如,出于分组和排序的目的,两个NULLs are considered equal. NULL被视为相等。That is, the 也就是说,GROUP BY clause arranges all NULLs in one group just like present values, and the ORDER BY clause sorts all NULLs together. GROUP BY子句将所有空值像现值一样排列在一个组中,ORDER BY子句将所有空值排序在一起。Standard SQL leaves it to the product implementation to determine whether 标准SQL让产品实现决定NULLs sort before present values or after them, but it must be consistent within the implementation. NULL是在当前值之前排序,还是在当前值之后排序,但它必须在实现中保持一致。T-SQL sorts T-SQL将NULLs before present values.NULL值排序在当前值之前。
As mentioned earlier, query filters “accept 如前所述,查询筛选器“接受TRUE.” TRUE”。An expression comparing two 比较两个NULLs yields UNKNOWN; therefore, such a row is filtered out.NULL值的表达式产生UNKNOWN结果;因此,这样一行被筛选掉。
For the purposes of enforcing a 为了强制执行UNIQUE constraint, standard SQL treats NULLs as different from each other (allowing multiple NULLs). UNIQUE约束,标准SQL将null视为彼此不同(允许多个null)。Conversely, in T-SQL, a 相反,在T-SQL中,UNIQUE constraint considers two NULLs as equal (allowing only one NULL).UNIQUE约束将两个NULL视为相等(只允许一个NULL)。
The complexity in handling 处理NULLs often results in logical errors. NULL值的复杂性通常会导致逻辑错误。Therefore, you should think about them in every query you write. 因此,您应该在编写的每个查询中考虑它们。If the default treatment is not what you want, you must intervene explicitly; otherwise, just ensure that the default behavior is, in fact, what you want.如果默认治疗不是你想要的,你必须明确干预;否则,只需确保默认行为实际上是您想要的。
SQL supports a concept called SQL支持一种称为“一次性操作”的概念,这意味着在同一逻辑查询处理阶段出现的所有表达式都在同一时间点进行逻辑计算。all-at-once operations, which means that all expressions that appear in the same logical query processing phase are evaluated logically at the same point in time. The reason for this is that all expressions that appear in the same logical phase are treated as a set, and as mentioned earlier, a set has no order to its elements.原因是,出现在同一逻辑阶段的所有表达式都被视为一个集合,如前所述,集合对其元素没有顺序。
This concept explains why, for example, you cannot refer to column aliases assigned in the 这个概念解释了为什么不能在同一个SELECT clause within the same SELECT clause. SELECT子句中引用SELECT子句中指定的列别名。Consider the following query:考虑下面的查询:
SELECT
orderid,
YEAR(orderdate) AS orderyear,
orderyear + 1 AS nextyear
FROM Sales.Orders;
The reference to the column alias 在选择列表的第三个表达式中,对列别名orderyear in the third expression in the SELECT list is invalid, even though the referencing expression appears to the right of the one in which the alias is assigned. orderyear的引用无效,即使引用表达式显示在分配别名的表达式的右侧。The reason is that logically there is no order of evaluation of the expressions in the 原因是,从逻辑上讲,SELECT clause—it is a set of expressions. SELECT子句中的表达式没有计算顺序,而是一组表达式。Conceptually, all the expressions are evaluated at the same point in time. 从概念上讲,所有表达式都是在同一时间点求值的。Therefore, this query generates the following error:因此,此查询生成以下错误:
Msg 207, Level 16, State 1, Line 4
Invalid column name 'orderyear'.
Here's another example for the ramifications of all-at-once operations: Suppose you have a table called 下面是另一个“一次完成所有操作”的结果示例:假设有一个名为T1 with two integer columns called col1 and col2, and you want to return all rows for which col2/col1 is greater than 2. T1的表,其中有两个整数列,分别为col1和col2,并且希望返回col2/col1大于2的所有行。Because there might be rows in the table in which 因为表中可能有col1 is zero, you need to ensure that the division doesn't take place in those cases—otherwise, the query would fail because of a divide-by-zero error. col1为零的行,所以您需要确保在这些情况下不会进行除法,否则,查询将因“除以零”错误而失败。So you write a query using the following format:因此,您可以使用以下格式编写查询:
SELECT col1, col2
FROM dbo.T1
WHERE col1 <> 0 AND col2/col1 > 2;
You might very well assume SQL Server evaluates the expressions from left to right, and that if the expression 您很可能会假设SQL Server从左到右计算表达式,如果表达式col1 <> 0 evaluates to FALSE, SQL Server will short-circuit—that is, that it won't bother to evaluate the expression 10/col1 > 2 because at this point it is known that the whole expression is FALSE. col1<>0的计算结果为FALSE,SQL Server将短路,也就是说,它不会费心计算表达式10/col1>2,因为此时已知整个表达式为FALSE。So you might think that this query should never produce a divide-by-zero error.所以你可能会认为这个查询永远不会产生被零除的错误。
SQL Server does support short circuits, but because of the all-at-once operations concept, it is free to process the expressions in the SQL Server确实支持短路,但由于“一次全部”操作的概念,它可以自由地以任何顺序处理WHERE clause in any order. WHERE子句中的表达式。SQL Server usually makes decisions like this based on cost estimations. SQL Server通常根据成本估算做出这样的决策。You can see that if SQL Server decides to process the expression 您可以看到,如果SQL Server决定先处理表达式10/col1 > 2 first, this query might fail because of a divide-by-zero error.10/col1>2,则此查询可能会因为被零除错误而失败。
You have several ways to avoid a failure here. 这里有几种避免失败的方法。For example, the order in which the 例如,WHEN clauses of a CASE expression are evaluated is guaranteed. CASE表达式的WHEN子句的求值顺序是有保证的。So you could revise the query as follows:因此,您可以按如下方式修改查询:
SELECT col1, col2
FROM dbo.T1
WHERE
CASE
WHEN col1 = 0 THEN 'no' -- or 'yes' if row should be returned
WHEN col2/col1 > 2 THEN 'yes'
ELSE 'no'
END = 'yes';
In rows where 在col1 is equal to zero, the first WHEN clause evaluates to TRUE and the CASE expression returns the string 'no'. col1等于零的行中,第一个WHEN子句的计算结果为TRUE,CASE表达式返回字符串'no'。(Replace (如果要在'no' with 'yes' if you want to return the row when col1 is equal to zero.) col1等于零时返回行,请将'no'替换为'yes'。)Only if the first 只有当第一个CASE expression does not evaluate to TRUE—meaning that col1 is not 0—does the second WHEN clause check whether the expression col2/col1 > 2 evaluates to TRUE. CASE表达式的计算结果不为TRUE,即col1不是0时,第二个WHEN子句才会检查表达式col2/col1>2的计算结果是否为TRUE。If it does, the 如果是,CASE expression returns the string 'yes'. CASE表达式将返回字符串'yes'。In all other cases, the 在所有其他情况下,CASE expression returns the string 'no'. CASE表达式返回字符串'no'。The predicate in the WHERE clause returns TRUE only when the result of the CASE expression is equal to the string 'yes'. WHERE子句中的谓词仅在CASE表达式的结果等于字符串'yes'时才返回TRUE。This means that there will never be an attempt here to divide by zero.这意味着这里永远不会有被零除的尝试。
This workaround turned out to be quite convoluted. 这个解决方法原来相当复杂。In this particular case, you can use a mathematical workaround that avoids division altogether:在这种特殊情况下,您可以使用一种数学解决方法,完全避免除法:
SELECT col1, col2
FROM dbo.T1
WHERE (col1 > 0 AND col2 > 2*col1) OR (col1 < 0 AND col2 < 2*col1);
I included this example to explain the unique and important concept of all-at-once operations and to elaborate on the fact that SQL Server guarantees the processing order of the 我加入这个例子是为了解释一次性操作的独特而重要的概念,并详细说明SQL Server保证WHEN clauses in a CASE expression.CASE表达式中WHEN子句的处理顺序这一事实。
In this section, I cover query manipulation of character data—including data types, collation, and operators and functions—and pattern matching.在本节中,我将介绍字符数据的查询操作,包括数据类型、排序、运算符和函数以及模式匹配。
SQL Server supports two kinds of character data types: regular and Unicode. SQL Server支持两种Unicode和常规字符类型。Regular data types include 常规数据类型包括CHAR and VARCHAR, and Unicode data types include NCHAR and NVARCHAR. CHAR和VARCHAR,Unicode数据类型包括NCHAR和NVARCHAR。Regular characters use 1 byte of storage for each character, whereas Unicode data requires 2 bytes per character, and in cases in which a surrogate pair is needed, 4 bytes are required. 常规字符每个字符使用1字节的存储空间,而Unicode数据每个字符需要2字节,如果需要代理对,则需要4字节。(For details on surrogate pairs, see (有关代理项对的详细信息,请参阅https://msdn.microsoft.com/en-us/library/windows/desktop/dd374069.) https://msdn.microsoft.com/en-us/library/windows/desktop/dd374069。)If you choose a regular character type for a column, you are restricted to only one language in addition to English. 如果为列选择常规字符类型,则除英语外,只能使用一种语言。The language support for the column is determined by the column's effective collation, which I'll describe shortly. 该列的语言支持取决于该列的有效排序,我将在稍后介绍。With Unicode data types, multiple languages are supported. 对于Unicode数据类型,支持多种语言。So if you store character data in multiple languages, make sure that you use Unicode character types and not regular ones.因此,如果您以多种语言存储字符数据,请确保使用Unicode字符类型,而不是常规字符类型。
The two kinds of character data types also differ in the way in which literals are expressed. 这两种字符数据类型的文字表达方式也不同。When expressing a regular character literal, you simply use single quotes: 当表达常规字符文字时,只需使用单引号:'This is a regular character string literal'. 'This is a regular character string literal'。When expressing a Unicode character literal, you need to specify the character 表达Unicode字符文字时,需要将字符N (for National) as a prefix: N'This is a Unicode character string literal'.N(代表“自然”)指定为前缀:N'This is a Unicode character string literal'。
Any data type without the 任何名称中没有VAR element (CHAR, NCHAR) in its name has a fixed length, which means that SQL Server preserves space in the row based on the column's defined size and not on the actual number of characters in the character string. VAR元素(CHAR,NCHAR)的数据类型都有固定的长度,这意味着SQL Server会根据列的定义大小而不是字符串中的实际字符数保留行中的空间。For example, when a column is defined as 例如,当一列被定义为CHAR(25), SQL Server preserves space for 25 characters in the row regardless of the length of the stored character string. CHAR(25)时,SQL Server会为行中的25个字符保留空间,而不管存储的字符串的长度如何。Because no expansion of the row is required when the strings are expanded, fixed-length data types are more suited for write-focused systems. 因为扩展字符串时不需要扩展行,所以固定长度的数据类型更适合于以写为中心的系统。But because storage consumption is not optimal with fixed-length strings, you pay more when reading data.但是,由于固定长度字符串的存储消耗不是最优的,所以在读取数据时需要支付更多的费用。
A data type with the 名称中包含VAR element (VARCHAR, NVARCHAR) in its name has a variable length, which means that SQL Server uses as much storage space in the row as required to store the characters that appear in the character string, plus two extra bytes for offset data. VAR元素(VARCHAR,NVARCHAR)的数据类型的长度是可变的,这意味着SQL Server在存储字符串中出现的字符时,在行中使用了所需的存储空间,另外两个字节用于偏移数据。For example, when a column is defined as 例如,当一个列被定义为VARCHAR(25), the maximum number of characters supported is 25, but in practice, the actual number of characters in the string determines the amount of storage. VARCHAR(25)时,支持的最大字符数是25,但实际上,字符串中的实际字符数决定了存储量。Because storage consumption for these data types is less than that for fixed-length types, read operations are faster. 因为这些数据类型的存储消耗比固定长度类型的存储消耗少,所以读取操作更快。However, updates might result in row expansion, which might result in data movement outside the current page. 但是,更新可能会导致行扩展,这可能会导致数据移动到当前页面之外。Therefore, updates of data having variable-length data types are less efficient than updates of data having fixed-length data types.因此,具有可变长度数据类型的数据更新的效率低于具有固定长度数据类型的数据更新的效率。
 Note
Note
If compression is used, the storage requirements change. 如果使用压缩,存储需求会发生变化。For details about compression, see “Data Compression” in SQL Server Books Online at 有关压缩的详细信息,请参阅SQL Server联机丛书中的“数据压缩”http://msdn.microsoft.com/en-us/library/cc280449.aspx.http://msdn.microsoft.com/en-us/library/cc280449.aspx。
You can also define the variable-length data types with the 还可以使用MAX specifier instead of a maximum number of characters. MAX说明符(而不是最大字符数)定义可变长度数据类型。When the column is defined with the 当使用MAX specifier, any value with a size up to a certain threshold (8,000 bytes by default) can be stored inline in the row (as long as it can fit in the row). MAX说明符定义列时,任何大小不超过某个阈值(默认情况下为8000字节)的值都可以内联存储在行中(只要它可以放入行中)。Any value with a size above the threshold is stored external to the row as a large object (LOB).大小大于阈值的任何值都将作为大对象(LOB)存储在行外部。
Later in this chapter, in the “Querying metadata” section, I explain how you can obtain metadata information about objects in the database, including the data types of columns.在本章后面的“查询元数据”部分,我将解释如何获取数据库中对象的元数据信息,包括列的数据类型。
Collation is a property of character data that encapsulates several aspects: language support, sort order, case sensitivity, accent sensitivity, and more. 排序规则是字符数据的一种属性,它封装了几个方面:语言支持、排序顺序、区分大小写、区分重音等等。To get the set of supported collations and their descriptions, you can query the table function 要获取受支持的排序规则集及其描述,可以按如下方式查询表函数fn_helpcollations as follows:fn_helpcollations:
SELECT name, description
FROM sys.fn_helpcollations();
For example, the following list explains the collation 例如,以下列表解释了排序规则Latin1_General_CI_AS:Latin1_General_CI_AS:
Latin1_General Code page 1252 is used. 使用代码页1252。(This supports English and German characters, as well as characters used by most Western European countries.)(这支持英语和德语字符,以及大多数西欧国家使用的字符。)
Dictionary sorting字典排序 Sorting and comparison of character data are based on dictionary order (A and a < B and b).字符数据的排序和比较基于字典顺序(A和a<B和b)。
You can tell that dictionary order is used because that's the default when no other ordering is defined explicitly. 因为当字典没有明确定义其他的顺序时,你可以告诉它。More specifically, the element 更具体地说,元素BIN doesn't explicitly appear in the collation name. BIN没有显式地出现在排序规则名称中。If the element 如果出现元素BIN appeared, it would mean that the sorting and comparison of character data was based on the binary representation of characters (A < B < a < b).BIN,则意味着字符数据的排序和比较基于字符的二进制表示(A<B<a<b)。
CI The data is case insensitive (a = A).数据不区分大小写(a=A)。
AS The data is accent sensitive (à <> ä).数据区分重音(à<>ä)。
In an on-premises SQL Server implementation, collation can be defined at four different levels: instance, database, column, and expression. 在内部部署的SQL Server实现中,可以在四个不同的级别定义排序规则:实例、数据库、列和表达式。The lowest effective level is the one that should be used. 最低有效水平是应该使用的水平。In Azure SQL Database, collation can be defined at the database, column, and expression levels. 在Azure SQL数据库中,可以在数据库、列和表达式级别定义排序规则。There are some specialized aspects of collation in contained databases. 在包含的数据库中,排序有一些特殊的方面。(For details, see (有关详细信息,请参阅https://msdn.microsoft.com/en-GB/library/ff929080.aspx.)https://msdn.microsoft.com/en-GB/library/ff929080.aspx。)
The collation of the instance is chosen as part of the setup program. 实例的排序规则被选为安装程序的一部分。It determines the collations of all system databases and is used as the default for user databases.它确定所有系统数据库的排序规则,并用作用户数据库的默认值。
When you create a user database, you can specify a collation for the database by using the 创建用户数据库时,可以使用COLLATE clause. COLLATE子句为数据库指定排序规则。If you don't, the instance's collation is assumed by default.如果没有,则默认情况下将采用实例的排序规则。
The database collation determines the collation of the metadata of objects in the database and is used as the default for user table columns. 数据库排序规则确定数据库中对象元数据的排序规则,并用作用户表列的默认值。I want to emphasize the importance of the fact that the database collation determines the collation of the metadata, including object and column names. 我想强调一个重要事实,即数据库排序规则决定元数据的排序规则,包括对象和列名。For example, if the database collation is case insensitive, you can't create two tables called 例如,如果数据库排序规则不区分大小写,则不能在同一架构中创建两个名为T1 and t1 within the same schema, but if the database collation is case sensitive, you can do that. T1和T1的表,但如果数据库排序规则区分大小写,则可以这样做。Note, though, that the collation aspects of variable and parameter identifiers are determined by the instance and not the database collation, regardless of the database you are connected to when declaring them. 但是请注意,变量和参数标识符的排序规则方面是由实例而不是数据库排序规则决定的,无论在声明它们时连接到哪个数据库。For example, if your instance has a case-insensitive collation and your database has a case-sensitive collation, you won't be able to define two variables or parameters named 例如,如果实例具有不区分大小写的排序规则,而数据库具有区分大小写的排序规则,则无法在同一范围内定义两个名为@p and @P in the same scope. @p和@P的变量或参数。Such an attempt will result in an error saying that the variable name has already been declared.这样的尝试将导致一个错误,表明变量名已经声明。
You can explicitly specify a collation for a column as part of its definition by using the 可以使用COLLATE clause. COLLATE子句为列显式指定排序规则,作为其定义的一部分。If you don't, the database collation is assumed by default.如果没有,默认情况下将采用数据库排序规则。
You can convert the collation of an expression by using the 可以使用COLLATE clause. COLLATE子句转换表达式的排序规则。For example, in a case-insensitive environment, the following query uses a case-insensitive comparison:例如,在不区分大小写的环境中,以下查询使用不区分大小写的比较:
SELECT empid, firstname, lastname
FROM HR.Employees
WHERE lastname = N'davis';
The query returns the row for Sara Davis, even though the casing doesn't match, because the effective casing is insensitive:查询返回Sara Davis的行,即使大小写不匹配,因为有效大小写不敏感:
empid firstname lastname
----------- ---------- --------------------
1 Sara Davis
If you want to make the filter case sensitive even though the column's collation is case insensitive, you can convert the collation of the expression:如果要使筛选器区分大小写,即使列的排序规则不区分大小写,也可以转换表达式的排序规则:
SELECT empid, firstname, lastname
FROM HR.Employees
WHERE lastname COLLATE Latin1_General_CS_AS = N'davis';
This time the query returns an empty set because no match is found when a case-sensitive comparison is used.这次查询返回一个空集,因为使用区分大小写的比较时找不到匹配项。
Quoted identifiers引用标识符
In standard SQL, single quotes are used to delimit literal character strings (for example, 在标准SQL中,单引号用于分隔文字字符串(例如'literal') and double quotes are used to delimit irregular identifiers such as table or column names that include a space or start with a digit (for example, “Irregular Identifier”). 'literal'),双引号用于分隔不规则标识符,例如包含空格或以数字开头的表名或列名(例如“Irregular Identifier”)。In SQL Server, there's a setting called 在SQL Server中,有一个名为QUOTED_IDENTIFIER that controls the meaning of double quotes. QUOTED_IDENTIFIER的设置,用于控制双引号的含义。You can apply this setting either at the database level by using the 可以使用ALTER DATABASE command or at the session level by using the SET command. ALTER DATABASE命令在数据库级别应用此设置,也可以使用SET命令在会话级别应用此设置。When the setting is turned on, the behavior is determined according to standard SQL, meaning that double quotes are used to delimit identifiers. 打开该设置后,将根据标准SQL确定行为,这意味着使用双引号来分隔标识符。When the setting is turned off, the behavior is nonstandard, and double quotes are used to delimit literal character strings. 关闭该设置时,行为是非标准的,双引号用于分隔文字字符串。It is strongly recommended that you follow best practices and use standard behavior (with the setting on). 强烈建议您遵循最佳实践并使用标准行为(设置为on)。Most database interfaces, including OLE DB and ODBC, turn this setting on by default.大多数数据库接口,包括OLEDB和ODBC,默认情况下都会启用此设置。
 Tip
Tip
As an alternative to using double quotes to delimit identifiers, T-SQL also supports square brackets (for example, 作为使用双引号分隔标识符的替代方法,T-SQL还支持方括号(例如,[Irregular Identifier]).[Irregular Identifier])。
Regarding single quotes that are used to delimit literal character strings, if you want to incorporate a single quote character as part of the string, you need to specify two single quotes. 关于用于分隔文字字符串的单引号,如果希望将单引号字符合并为字符串的一部分,则需要指定两个单引号。For example, to express the literal 例如,要表示文字abc'de, specify 'abc''de'.abc'de,请指定'abc''de'。
This section covers string concatenation and functions that operate on character strings. 本节介绍字符串连接和对字符串进行操作的函数。For string concatenation, T-SQL provides the plus-sign (+) operator and the 对于字符串连接,T-SQL提供加号(+)运算符和CONCAT function. CONCAT函数。For other operations on character strings, T-SQL provides several functions, including 对于字符串的其他操作,T-SQL提供了几个函数,包括SUBSTRING, LEFT, RIGHT, LEN, DATALENGTH, CHARINDEX, PATINDEX, REPLACE, REPLICATE, STUFF, UPPER, LOWER, RTRIM, LTRIM, FORMAT, COMPRESS, DECOMPRESS, and STRING_SPLIT. SUBSTRING、LEFT、RIGHT、LEN、DATALENGTH、CHARINDEX、PATINDEX、REPLACE、REPLICATE、STUFF、UPPER、LOWER、RTRIM、LTRIM、FORMAT、COMPRESS、DECOMPRESS和STRING_SPLIT。In the following sections, I describe these commonly used operators and functions. 在以下几节中,我将介绍这些常用的运算符和函数。Note that there is no SQL standard functions library—they are all implementation-specific.请注意,没有SQL标准函数库,它们都是特定于实现的。
CONCAT function)CONCAT函数)T-SQL provides the plus-sign (+) operator and the T-SQL提供加号(+)运算符和CONCAT function to concatenate strings. CONCAT函数来连接字符串。For example, the following query against the 例如,以下针对Employees table produces the fullname result column by concatenating firstname, a space, and lastname:Employees表的查询通过连接firstname、空格和lastname生成fullname结果列:
SELECT empid, firstname + N' ' + lastname AS fullname
FROM HR.Employees;
This query produces the following output:此查询生成以下输出:
empid fullname
----------- -------------------------------
1 Sara Davis
2 Don Funk
3 Judy Lew
4 Yael Peled
5 Sven Mortensen
6 Paul Suurs
7 Russell King
8 Maria Cameron
9 Patricia Doyle
Standard SQL dictates that a concatenation with a 标准SQL规定,带有NULL should yield a NULL. NULL的串联应产生NULL。This is the default behavior of T-SQL. 这是T-SQL的默认行为。For example, consider the query against the 例如,考虑对Listing 2-7所示的Customers table shown in Listing 2-7.Customers的查询。
LISTING 2-7 Query demonstrating string concatenation显示字符串连接的查询
SELECT custid, country, region, city,
country + N',' + region + N',' + city AS location
FROM Sales.Customers;
Some of the rows in the Customers table have a NULL in the region column. Customers表中的某些行在region列中有空值。For those, SQL Server returns by default a 对于这些,SQL Server默认情况下会在“位置结果”列中返回NULL in the location result column:NULL:
custid country region city location
----------- --------------- ------- --------------- --------------------
1 Germany NULL Berlin NULL
2 Mexico NULL México D.F. NULL
3 Mexico NULL México D.F. NULL
4 UK NULL London NULL
5 Sweden NULL Luleå NULL
6 Germany NULL Mannheim NULL
7 France NULL Strasbourg NULL
8 Spain NULL Madrid NULL
9 France NULL Marseille NULL
10 Canada BC Tsawwassen Canada,BC,Tsawwassen
11 UK NULL London NULL
12 Argentina NULL Buenos Aires NULL
13 Mexico NULL México D.F. NULL
14 Switzerland NULL Bern NULL
15 Brazil SP Sao Paulo Brazil,SP,Sao Paulo
16 UK NULL London NULL
17 Germany NULL Aachen NULL
18 France NULL Nantes NULL
19 UK NULL London NULL
20 Austria NULL Graz NULL
...
(91 row(s) affected)
To treat a 要将NULL as an empty string—or more accurately, to substitute a NULL with an empty string—you can use the COALESCE function. NULL视为空字符串,或者更准确地说,要用空字符串替换NULL,可以使用COALESCE函数。This function accepts a list of input values and returns the first that is not 此函数接受输入值列表,并返回第一个非NULL. NULL值。Here's how you can revise the query from Listing 2-7 to programmatically substitute 下面是如何修改Listing 2-7中的查询,以编程方式用空字符串替换NULLs with empty strings:null:
SELECT custid, country, region, city,
country + COALESCE( N',' + region, N'') + N',' + city AS location
FROM Sales.Customers;
T-SQL supports a function called T-SQL支持一个名为CONCAT that accepts a list of inputs for concatenation and automatically substitutes NULLs with empty strings. CONCAT的函数,该函数接受用于连接的输入列表,并自动用空字符串替换NULL值。For example, the expression 例如,表达式CONCAT('a', NULL, 'b') returns the string 'ab'.CONCAT('a', NULL, 'b')返回字符串'ab'。
Here's how to use the 下面是如何使用CONCAT function to concatenate the customer's location elements, replacing NULLs with empty strings:CONCAT函数连接客户的location元素,用空字符串替换null:
SELECT custid, country, region, city,
CONCAT(country, N',' + region, N',' + city) AS location
FROM Sales.Customers;
SUBSTRING functionSUBSTRING函数The SUBSTRING function extracts a substring from a string.SUBSTRING函数从字符串中提取一个子字符串。
SUBSTRING(string, start, length)
This function operates on the input 此函数对输入string and extracts a substring starting at position start that is length characters long. string进行操作,并提取一个子字符串,该子字符串从位置start开始,长度为length个字符。For example, the following code returns the output 'abc':例如,以下代码返回输出'abc':
SELECT SUBSTRING('abcde', 1, 3);
If the value of the third argument exceeds the end of the input string, the function returns everything until the end without raising an error. 如果第三个参数的值超过输入字符串的结尾,则函数将返回所有内容,直到结束,而不会引发错误。This can be convenient when you want to return everything from a certain point until the end of the string—you can simply specify the maximum length of the data type or a value representing the full length of the input string.当您希望返回从某一点到字符串结束的所有内容时,这非常方便。您可以简单地指定数据类型的最大长度或表示输入字符串全长的值。
LEFT and RIGHT functionsLEFT函数和RIGHT函数The LEFT and RIGHT functions are abbreviations of the SUBSTRING function, returning a requested number of characters from the left or right end of the input string.LEFT和RIGHT函数是SUBSTRING函数的缩写,从输入字符串的左端或右端返回请求的字符数。
LEFT(, string, n)RIGHT(string, n)
The first argument, 第一个参数string, is the string the function operates on. string是函数操作的字符串。The second argument, 第二个参数n, is the number of characters to extract from the left or right end of the string. n是从字符串的左端或右端提取的字符数。For example, the following code returns the output 'cde':例如,以下代码返回输出'cde':
SELECT RIGHT('abcde', 3);
LEN and DATALENGTH functionsLEN函数和DATALENGTH函数The LEN function returns the number of characters in the input string.LEN函数返回输入字符串中的字符数。
LEN(string)
Note that this function returns the number of characters in the input string and not necessarily the number of bytes. 请注意,此函数返回输入字符串中的字符数,而不一定是字节数。With regular characters, both numbers are the same because each character requires 1 byte of storage. 对于常规字符,两个数字是相同的,因为每个字符需要1字节的存储空间。With Unicode characters, each character requires at least 2 bytes of storage (in most cases, at least); therefore, the number of characters is half the number of bytes. 对于Unicode字符,每个字符至少需要2个字节的存储空间(在大多数情况下,至少需要2个字节);因此,字符数是字节数的一半。To get the number of bytes, use the 要获取字节数,请使用DATALENGTH function instead of LEN. For example, the following code returns 5:DATALENGTH函数而不是LEN。例如,以下代码返回5:
SELECT LEN(N'abcde');
The following code returns 10:以下代码返回10:
SELECT DATALENGTH(N'abcde');
Another difference between LEN and DATALENGTH is that the former excludes trailing blanks but the latter doesn't.LEN和DATALENGTH之间的另一个区别是前者不包括尾随空格,但后者包括尾随空格。
CHARINDEX functionCHARINDEX函数The CHARINDEX function returns the position of the first occurrence of a substring within a string.CHARINDEX函数返回子字符串在字符串中第一次出现的位置。
CHARINDEX(substring, string[, start_pos])
This function returns the position of the first argument, 此函数返回第一个参数substring, within the second argument, string. substring在第二个参数string中的位置。You can optionally specify a third argument, 您可以选择指定第三个参数start_pos, to tell the function the position from which to start looking. start_pos,告诉函数开始查找的位置。If you don't specify the third argument, the function starts looking from the first character. 如果不指定第三个参数,函数将从第一个字符开始查看。If the substring is not found, the function returns 0. 如果未找到子字符串,则函数返回0。For example, the following code returns the first position of a space in 例如,以下代码返回空间在'Itzik Ben-Gan', so it returns the output 6:'Itzik Ben-Gan'中的第一个位置,因此返回输出6:
SELECT CHARINDEX(' ','Itzik Ben-Gan');
PATINDEX functionPATINDEX函数The PATINDEX function returns the position of the first occurrence of a pattern within a string.PATINDEX函数返回字符串中第一个模式出现的位置。
PATINDEX(pattern, string)
The argument 参数pattern uses similar patterns to those used by the LIKE predicate in T-SQL. pattern使用的模式与T-SQL中LIKE谓词使用的模式类似。I'll explain patterns and the 我将在本章后面的LIKE predicate later in this chapter, in “The LIKE predicate” section. LIKE谓词部分解释模式和LIKE谓词。Even though I haven't explained yet how patterns are expressed in T-SQL, I include the following example here to show how to find the position of the first occurrence of a digit within a string:尽管我还没有解释如何在t-SQL中表达模式,但我在这里提供了以下示例,以展示如何找到字符串中第一个数字出现的位置:
SELECT PATINDEX('%[0-9]%', 'abcd123efgh');
This code returns the output 5.此代码返回输出5。
REPLACE functionREPLACE函数The REPLACE function replaces all occurrences of a substring with another.REPLACE函数用另一个子字符串替换所有出现的子字符串。
REPLACE(string, substring1, substring2)
The function replaces all occurrences of 该函数将substring1 in string with substring2. string中出现的所有substring1替换为substring2。For example, the following code substitutes all occurrences of a dash in the input string with a colon:例如,以下代码用冒号替换输入字符串中所有出现的破折号:
SELECT REPLACE('1-a 2-b', '-', ':');
This code returns the output: '1:a 2:b'.此代码返回输出:'1:a 2:b'。
You can use the 可以使用REPLACE function to count the number of occurrences of a character within a string. REPLACE函数计算字符串中字符的出现次数。To do this, you replace all occurrences of the character with an empty string (zero characters) and calculate the original length of the string minus the new length. 为此,将所有出现的字符替换为空字符串(零个字符),并计算字符串的原始长度减去新长度。For example, the following query returns, for each employee, the number of times the character 例如,下面的查询,对每个雇员,返回在e appears in the lastname attribute:lastname属性中字符e出现的次数。
SELECT empid, lastname,
LEN(lastname) - LEN(REPLACE(lastname, 'e', '')) AS numoccur
FROM HR.Employees;
This query generates the following output:此查询生成以下输出:
empid lastname numoccur
----------- -------------------- -----------
8 Cameron 1
1 Davis 0
9 Doyle 1
2 Funk 0
7 King 0
3 Lew 1
5 Mortensen 2
4 Peled 2
6 Suurs 0
REPLICATE functionREPLICATE函数The REPLICATE function replicates a string a requested number of times.REPLICATE函数按请求的次数复制字符串。
REPLICATE(string, n)
For example, the following code replicates the string 'abc' three times, returning the string 'abcabcabc':例如,以下代码将字符串'abc'复制三次,并返回字符串'abcabcabc':
SELECT REPLICATE('abc', 3);
The next example demonstrates the use of the 下一个示例演示了REPLICATE function, along with the RIGHT function and string concatenation. REPLICATE函数的使用,以及RIGHT函数和字符串连接。The following query against the 以下针对Production.Suppliers table generates a 10-digit string representation of the supplier ID integer with leading zeros:Production.Suppliers表的查询生成了供应商ID整数的10位字符串表示形式,前导为零:
SELECT supplierid,
RIGHT(REPLICATE('0', 9) + CAST(supplierid AS VARCHAR(10)), 10) AS strsupplierid
FROM Production.Suppliers;
The expression producing the result column 生成结果列strsupplierid replicates the character 0 nine times (producing the string '000000000') and concatenates the string representation of the supplier ID. strsupplierid的表达式将字符0复制九次(生成字符串'000000000'),并连接供应商ID的字符串表示形式。The CAST function converts the original integer supplier ID to a string data type (VARCHAR). CAST函数将原始整数供应商ID转换为字符串数据类型(VARCHAR)。Finally, the 最后,RIGHT function extracts the 10 rightmost characters of the result string. Here's the output of this query, shown in abbreviated form:RIGHT函数提取结果字符串最右边的10个字符。以下是该查询的输出,以缩写形式显示:
supplierid strsupplierid
----------- -------------
29 0000000029
28 0000000028
4 0000000004
21 0000000021
2 0000000002
22 0000000022
14 0000000014
11 0000000011
25 0000000025
7 0000000007
...
(29 row(s) affected)
Note that T-SQL supports a function called 请注意,T-SQL支持一个名为FORMAT that you can use to achieve such formatting needs much more easily, though at a higher cost. FORMAT的函数,您可以使用它更容易地实现这种格式化需求,尽管代价更高。I'll describe it later in this section.我将在本节后面描述它。
STUFF functionSTUFF函数You use the 可以使用STUFF function to remove a substring from a string and insert a new substring instead.STUFF函数从字符串中删除一个子字符串,然后插入一个新的子字符串。
STUFF(string, pos, delete_length, insert_string)
This function operates on the input parameter 此函数对输入参数string. string进行操作。It deletes as many characters as the number specified in the 它从delete_length parameter, starting at the character position specified in the pos input parameter. pos输入参数中指定的字符位置开始,删除与delete_length参数中指定的数字相同的字符数。The function inserts the string specified in the 该函数将insert_string parameter in position pos. insert_string参数中指定的字符串插入pos位置。For example, the following code operates on the string 'xyz', removes one character from the second character, and inserts the substring 'abc' instead:例如,以下代码对字符串'xyz'进行操作,从第二个字符中删除一个字符,并插入子字符串'abc':
SELECT STUFF('xyz', 2, 1, 'abc');
The output of this code is 'xabcz'.此代码的输出为'xabcz'。
If you just want to insert a string and not delete anything, you can specify a length of 0 as the third argument.如果只想插入字符串而不删除任何内容,可以指定长度0作为第三个参数。
UPPER and LOWER functionsUPPER函数和LOWER函数The UPPER and LOWER functions return the input string with all uppercase or lowercase characters, respectively.UPPER和LOWER函数分别返回包含所有大写或小写字符的输入字符串。
UPPER(, string)LOWER(string)
For example, the following code returns 'ITZIK BEN-GAN':例如,以下代码返回'ITZIK BEN-GAN':
SELECT UPPER('Itzik Ben-Gan');
The following code returns 'itzik ben-gan':以下代码返回'itzik ben-gan':
SELECT LOWER('Itzik Ben-Gan');
RTRIM and LTRIM functionsRTRIM函数和LTRIM函数The RTRIM and LTRIM functions return the input string with leading or trailing spaces removed.RTRIM和LTRIM函数返回删除前导或尾随空格的输入字符串。
RTRIM(, string)LTRIM(string)
If you want to remove both leading and trailing spaces, use the result of one function as the input to the other. 如果要同时删除前导空格和尾随空格,请使用一个函数的结果作为另一个函数的输入。For example, the following code removes both leading and trailing spaces from the input string, returning 'abc':例如,以下代码从输入字符串中删除前导空格和尾随空格,并返回'abc':
SELECT RTRIM(LTRIM(' abc '));
FORMAT functionFORMAT函数You use the 可以使用FORMAT function to format an input value as a character string based on a Microsoft .NET format string and an optional culture specification.FORMAT函数将输入值格式化为基于Microsoft .NET FORMAT字符串和可选区域性规范的字符串。
FORMAT(input , format_string, culture)
There are numerous possibilities for formatting inputs using both standard and custom format strings. 使用标准和自定义格式字符串格式化输入有多种可能性。The MSDN article at MSDN文章http://go.microsoft.com/fwlink/?LinkId=211776 provides more information. http://go.microsoft.com/fwlink/?LinkId=211776提供更多信息。But just as a simple example, recall the convoluted expression used earlier to format a number as a 10-digit string with leading zeros. 但作为一个简单的例子,回想一下前面使用的卷积表达式,它将数字格式化为带前导零的10位字符串。By using 通过使用FORMAT, you can achieve the same task with either the custom format string '0000000000' or the standard one, 'd10'. FORMAT,您可以使用自定义格式字符串'0000000000'或标准格式字符串'd10'完成相同的任务。As an example, the following code returns '0000001759':例如,以下代码返回'0000001759':
SELECT FORMAT(1759, '000000000');
Note
The FORMAT function is usually more expensive than alternative T-SQL functions that you use to format values. FORMAT函数通常比用于格式化值的替代T-SQL函数更昂贵。You should generally refrain from using it unless you are willing to accept the performance penalty. 除非你愿意接受性能惩罚,否则你通常应该避免使用它。As an example, I ran a query against a table with 1,000,000 rows to compute the 10-digit string representation of one of the integer columns. 例如,我对一个有1000000行的表运行了一个查询,以计算其中一个整数列的10位字符串表示形式。The query took close to a minute to complete on my computer with the 使用FORMAT function compared to under a second with the alternative method using the REPLICATE and RIGHT functions.FORMAT函数在我的计算机上完成查询需要将近一分钟的时间,而使用REPLICATE和RIGHT函数的替代方法需要不到一秒钟的时间。
COMPRESS函数和DECOMPRESS函数The COMPRESS and DECOMPRESS functions use the GZIP algorithm to compress and decompress the input, respectively. COMPRESS和DECOMPRESS函数分别使用GZIP算法对输入进行压缩和解压缩。Both functions were introduced in SQL Server 2016.SQL Server 2016中引入了这两种功能。
COMPRESS(, string)DECOMPRESS(string)
The COMPRESS function accepts a character or binary string as input and returns a compressed VARBINARY(MAX) typed value. COMPRESS函数接受一个字符或二进制字符串作为输入,并返回一个压缩的VARBINARY(MAX)类型的值。Here's an example for using the function with a constant as input:下面是一个使用常数作为输入的函数的示例:
SELECT COMPRESS(N'This is my cv. Imagine it was much longer.');
The result is a binary value holding the compressed form of the input string.结果是一个二进制值,保存输入字符串的压缩形式。
If you want to store the compressed form of input values in a column in a table, you need to apply the 如果要将输入值的压缩形式存储在表中的列中,则需要对输入值应用COMPRESS function to the input value and store the result in the table. COMPRESS函数,并将结果存储在表中。You can do this as part of the 这可以作为INSERT statement that adds the row to the target table. INSERT语句的一部分来完成,INSERT语句将行添加到目标表中。(For information about data modification, see Chapter 8.) (有关数据修改的信息,请参阅第8章。)For example, suppose you have a table called 例如,假设数据库中有一个名为EmployeeCVs in your database, with columns called empid and cv. EmployeeCVs的表,其中包含名为empid和cv的列。The column cv holds the compressed form of the employee's resume and is defined as VARBINARY(MAX). cv列保存员工简历的压缩格式,定义为VARBINARY(MAX)。Suppose you have a stored procedure called 假设有一个名为AddEmpCV that accepts input parameters called @empid and @cv. AddEmpCV的存储过程,它接受名为@empid和@cv的输入参数。(For information about stored procedures, see Chapter 11.) (有关存储过程的信息,请参阅第11章。)The parameter 参数@cv is the uncompressed form of the input employee's resume and is defined as NVARCHAR(MAX). @cv是输入员工简历的未压缩形式,定义为NVARCHAR(MAX)。The procedure is responsible for inserting a new row into the table with the compressed employee resume information. 该过程负责将压缩的员工简历信息插入表中的新行。The 存储过程中的INSERT statement within the stored procedure might look like this:INSERT语句可能如下所示:
INSERT INTO dbo.EmployeeCVs( empid, cv ) VALUES( @empid, COMPRESS(@cv) );
The DECOMPRESS function accepts a binary string as input and returns a decompressed VARBINARY(MAX) typed value. DECOMPRESS函数接受二进制字符串作为输入,并返回一个解压缩的VARBINARY(MAX)类型的值。Note that if the value you originally compressed was of a character string type, you will need to explicitly cast the result of the 请注意,如果最初压缩的值是字符串类型,则需要显式地将DECOMPRESS function to the target type. DECOMPRES函数的结果强制转换为目标类型。As an example, the following code doesn't return the original input value; rather, it returns a binary value:例如,以下代码不返回原始输入值;而是返回一个二进制值:
SELECT DECOMPRESS(COMPRESS(N'This is my cv. Imagine it was much longer.'));
To get the original value, you need to cast the result to the target character string type, like so:要获取原始值,需要将结果强制转换为目标字符串类型,如下所示:
SELECT
CAST(
DECOMPRESS(COMPRESS(N'This is my cv. Imagine it was much longer.'))
AS NVARCHAR(MAX));
Consider the 从前面的示例中考虑EmployeeCVs table from the earlier example. EmployeeCVs表。To return the uncompressed form of the employee resumes, you use the following query (don't run this code because this table doesn't actually exist):要返回未压缩的员工简历表单,请使用以下查询(不要运行此代码,因为此表实际上不存在):
SELECT empid, CAST(DECOMPRESS(cv) AS NVARCHAR(MAX)) AS cv
FROM dbo.EmployeeCVs;
STRING_SPLIT functionSTRING_SPLIT函数The STRING_SPLIT table function splits an input string with a separated list of values into the individual elements. STRING_SPLIT表函数将带有一个单独的值列表的输入字符串拆分为各个元素。This function was introduced in SQL Server 2016.SQL Server 2016中引入了此功能。
SELECT value FROM STRING_SPLIT(string, separator);
Unlike the string functions described so far, which are all scalar functions, the 与目前描述的字符串函数(都是标量函数)不同,STRING_SPLIT function is a table function. STRING_SPLIT函数是一个表函数。It accepts as inputs a string with a separated list of values plus a separator, and it returns a table result with a string column called 它接受一个字符串作为输入,该字符串包含一个单独的值列表和一个分隔符,并返回一个表结果,其中包含一个名为val with the individual elements. val的字符串列和各个元素。If you need the elements to be returned with a data type other than a character string, you will need to cast the 如果需要使用字符串以外的数据类型返回元素,则需要将val column to the target type. val列强制转换为目标类型。For example, the following code accepts the input string '10248,10249,10250' and separator ',' and it returns a table result with the individual elements:例如,下面的代码接受输入字符串'10248,10249,10250'和分隔符',',并返回带有单个元素的表结果:
SELECT CAST(value AS INT) AS myvalue
FROM STRING_SPLIT('10248,10249,10250', ',') AS S;
In this example, the input list contains values representing order IDs. 在本例中,输入列表包含表示订单ID的值。Because the IDs are supposed to be integers, the query converts the 因为val column to the INT data type. id应该是整数,所以查询将val列转换为INT数据类型。Here's the output of this code:下面是这段代码的输出:
myvalue
-----------
10248
10249
10250
A common use case for such splitting logic is passing a separated list of values representing keys, such as order IDs, to a stored procedure or user-defined function and returning the rows from some table, such as Orders, that have the input keys. 这种拆分逻辑的一个常见用例是将表示键(如order id)的单独值列表传递给存储过程或用户定义函数,并从具有输入键的某些表(如Orders)返回行。This is achieved by joining the 这是通过将STRING_SPLIT function with the target table and matching the keys from both sides.STRING_SPLIT函数与目标表连接并匹配两侧的键来实现的。
LIKE predicateLIKE谓词T-SQL provides a predicate called T-SQL提供了一个名为LIKE that you can use to check whether a character string matches a specified pattern. LIKE的谓词,可用于检查字符串是否与指定模式匹配。Similar patterns are used by the 前面描述的PATINDEX function described earlier. PATINDEX函数也使用了类似的模式。The following section describes the wildcards supported in the patterns and demonstrates their use.以下部分描述了模式中支持的通配符,并演示了它们的用法。
% (percent) wildcard%(百分号)通配符The percent sign represents a string of any size, including an empty string. 百分号表示任意大小的字符串,包括空字符串。For example, the following query returns employees where the last name starts with 例如,以下查询返回姓氏以D:D开头的员工:
SELECT empid, lastname
FROM HR.Employees
WHERE lastname LIKE N'D%';
This query returns the following output:此查询返回以下输出:
empid lastname
----------- --------------------
1 Davis
9 Doyle
Note that often you can use functions such as 请注意,通常可以使用SUBSTRING and LEFT instead of the LIKE predicate to represent the same meaning. SUBSTRING和LEFT等函数,而不是LIKE谓词来表示相同的含义。But the 但是LIKE predicate tends to get optimized better—especially when the pattern starts with a known prefix.LIKE谓词往往会得到更好的优化,尤其是当模式以已知前缀开头时。
_(下划线)通配符An underscore represents a single character. 下划线表示单个字符。For example, the following query returns employees where the second character in the last name is 例如,以下查询返回姓氏第二个字符为e:e的员工:
SELECT empid, lastname
FROM HR.Employees
WHERE lastname LIKE N'_e%';
This query returns the following output:此查询返回以下输出:
empid lastname
----------- --------------------
3 Lew
4 Peled
list of characters>] wildcard[<list of characters>]通配符Square brackets with a list of characters (such as 带有字符列表(如[ABC]) represent a single character that must be one of the characters specified in the list. [ABC])的方括号表示一个字符,该字符必须是列表中指定的字符之一。For example, the following query returns employees where the first character in the last name is 例如,以下查询返回姓氏第一个字符为A, B, or C:A、B或C的员工:
SELECT empid, lastname
FROM HR.Employees
WHERE lastname LIKE N'[ABC]%';
This query returns the following output:此查询返回以下输出:
empid lastname
----------- --------------------
8 Cameron
character>-<character>] wildcard[<character>-<character>]通配符Square brackets with a character range (such as 带有字符范围的方括号(例如[A-E]) represent a single character that must be within the specified range. [A-E])表示必须在指定范围内的单个字符。For example, the following query returns employees where the first character in the last name is a letter in the range 例如,以下查询返回姓氏中的第一个字符是A through E, inclusive, taking the collation into account:A到E(包括A和E)范围内的字母的员工,并考虑排序规则:
SELECT empid, lastname
FROM HR.Employees
WHERE lastname LIKE N'[A-E]%';
This query returns the following output:此查询返回以下输出:
empid lastname
----------- --------------------
8 Cameron
1 Davis
9 Doyle
character list or range>] wildcard[^<character list or range>]通配符Square brackets with a caret sign (^) followed by a character list or range (such as 带有插入符号([^A-E]) represent a single character that is not in the specified character list or range. ^)和字符列表或范围(例如[^A-E])的方括号表示不在指定字符列表或范围内的单个字符。For example, the following query returns employees where the first character in the last name is not a letter in the range 例如,以下查询返回姓氏中的第一个字符不是A through E:A到E范围内的字母的员工:
SELECT empid, lastname
FROM HR.Employees
WHERE lastname LIKE N'[^A-E]%';
This query returns the following output:此查询返回以下输出:
empid lastname
----------- --------------------
2 Funk
7 King
3 Lew
5 Mortensen
4 Peled
6 Suurs
ESCAPE characterESCAPE字符If you want to search for a character that is also used as a wildcard (such as %, _, [, or ]), you can use an escape character. 如果要搜索也用作通配符的字符(例如%、_、[或]),可以使用转义字符。Specify a character that you know for sure doesn't appear in the data as the escape character in front of the character you are looking for, and specify the keyword 指定一个您确信不会出现在数据中的字符作为转义字符出现在您要查找的字符前面,并指定关键字ESCAPE followed by the escape character right after the pattern. ESCAPE后跟模式后面的转义字符。For example, to check whether a column called 例如,要检查名为col1 contains an underscore, use col1 LIKE '%!_%' ESCAPE '!'.col1的列是否包含下划线,请使用类似col1 LIKE '%!_%' ESCAPE '!'。
For the wildcards %, _, and [, you can use square brackets instead of an escape character. 对于通配符%、_和[,可以使用方括号而不是转义字符。For example, instead of 例如,而不是使用col1 LIKE '%!_%' ESCAPE '!', you can use col1 LIKE '%[_]%'.col1 LIKE '%!_%' ESCAPE '!',而是使用col1 LIKE '%[_]%'。
Working with date and time data in SQL Server is not trivial. 在SQL Server中处理日期和时间数据并非易事。You will face several challenges in this area, such as expressing literals in a language-neutral manner and working with date and time separately.在这方面,您将面临一些挑战,例如以语言中立的方式表达文字,以及分别处理日期和时间。
In this section, I first introduce the date and time data types supported by SQL Server; then I explain the recommended way to work with those types; and finally I cover date- and time-related functions.在本节中,我首先介绍SQL Server支持的日期和时间数据类型;然后我解释了使用这些类型的推荐方法;最后,我将介绍与日期和时间相关的函数。
T-SQL supports six date and time data types: two legacy types called T-SQL支持六种日期和时间数据类型:两种称为DATETIME and SMALLDATETIME, and four later additions (since SQL Server 2008) called DATE, TIME, DATETIME2, and DATETIMEOFFSET. DATETIME和SMALLDATETIME的传统类型,以及四种更高版本的数据类型(自SQL Server 2008年以来),分别称为DATE、TIME、DATETIME2和DATETIMEOFFSET。The legacy types 旧式类型DATETIME and SMALLDATETIME include date and time components that are inseparable. DATETIME和SMALLDATETIME包含不可分割的日期和时间组件。The two types differ in their storage requirements, their supported date range, and their precision. 这两种类型在存储要求、支持的日期范围和精度方面有所不同。The 如果需要,DATE and TIME data types provide a separation between the date and time components if you need it. DATE和TIME数据类型在日期和时间组件之间提供分隔。The DATETIME2 data type has a bigger date range and better precision than the legacy types. DATETIME2数据类型的日期范围和精度比传统类型更大。The DATETIMEOFFSET data type is similar to DATETIME2, but it also includes the offset from UTC.DATETIMEOFFSET数据类型类似于DATETIME2,但它还包括来自UTC的偏移量。
Table 2-1 lists details about date and time data types, including storage requirements, supported date range, precision, and recommended entry format.Table 2-1列出了日期和时间数据类型的详细信息,包括存储要求、支持的日期范围、精度和建议的输入格式。
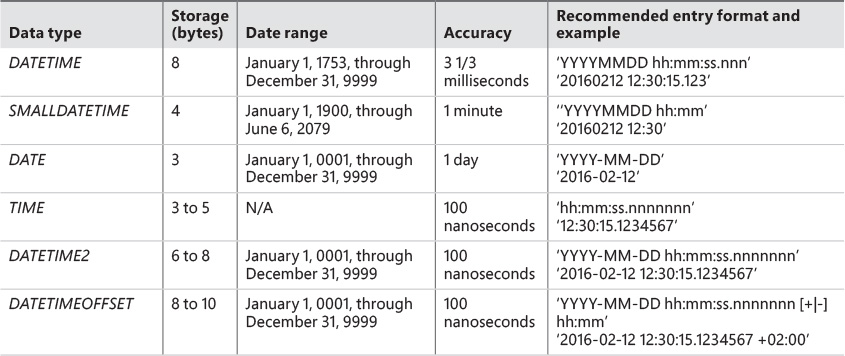
TABLE 2-1 Date and time data types日期和时间数据类型
The storage requirements for the last three data types in Table 2-1 (Table 2-1中最后三种数据类型(TIME, DATETIME2, and DATETIMEOFFSET) depend on the precision you choose. TIME、DATETIME2和DATETIMEOFFSET)的存储要求取决于您选择的精度。You specify a fractional-second precision as an integer in the range 0 to 7. 将小数秒精度指定为0到7范围内的整数。For example, 例如,TIME(0) means 0 fractional-second precision—in other words, one-second precision. TIME(0)意味着0分之一秒的精度,换句话说,一秒的精度。TIME(3) means one-millisecond precision, and TIME(7) means 100-nanosecond precision. TIME(3)表示一毫秒精度,TIME(7)表示100纳秒精度。If you don't specify a fractional-second precision, SQL Server assumes 7 by default. 如果不指定小数秒精度,SQL Server默认为7。When converting a value to a data type with a lower precision, it gets rounded to the closest expressible value in the target precision.将值转换为精度较低的数据类型时,会将其四舍五入到目标精度中最接近的可表达值。
When you need to specify a literal (constant) of a date and time data type, you should consider several things. 当需要指定日期和时间数据类型的文本(常量)时,应考虑几件事。First, though it might sound a bit strange, T-SQL doesn't provide the means to express a date and time literal; instead, you can specify a literal of a different type that can be converted—explicitly or implicitly—to a date and time data type. 首先,虽然听起来有点奇怪,但T-SQL并没有提供表示日期和时间文字的方法;相反,您可以指定不同类型的文本,该文本可以显式或隐式转换为日期和时间数据类型。It is a best practice to use character strings to express date and time values, as shown in the following example:最好使用字符串来表示日期和时间值,如下例所示:
SELECT orderid, custid, empid, orderdate
FROM Sales.Orders
WHERE orderdate = '20160212';
SQL Server recognizes the literal '20160212' as a character-string literal and not as a date and time literal, but because the expression involves operands of two different types, one operand needs to be implicitly converted to the other's type. SQL Server将文字'20160212'识别为字符串文字,而不是日期和时间文字,但由于表达式涉及两种不同类型的操作数,因此需要将一个操作数隐式转换为另一个操作数的类型。Normally, implicit conversion between types is based on what's called 通常,类型之间的隐式转换基于所谓的“数据类型优先级”。data-type precedence. SQL Server defines precedence among data types and will usually implicitly convert the operand that has a lower data-type precedence to the one that has higher precedence. SQL Server定义数据类型之间的优先级,通常会隐式地将数据类型优先级较低的操作数转换为优先级较高的操作数。In this example, the character-string literal is converted to the column's data type (在本例中,字符串文字被转换为列的数据类型(DATETIME) because character strings are considered lower in terms of data-type precedence with respect to date and time data types. DATETIME),因为字符串的数据类型优先级低于日期和时间数据类型。Implicit conversion rules are not always that simple. 隐式转换规则并不总是那么简单。In fact, different rules are applied with filters and in other expressions, but for the purposes of this discussion, I'll keep things simple. 事实上,不同的规则适用于筛选器和其他表达式,但出于讨论的目的,我将保持简单。For the complete description of data-type precedence, see “Data Type Precedence” in SQL Server Books Online.有关数据类型优先级的完整描述,请参阅SQL Server联机丛书中的“数据类型优先级”。
The point I'm trying to make is that in the preceding example, implicit conversion takes place behind the scenes. 我想说的是,在前面的例子中,隐式转换发生在幕后。This query is logically equivalent to the following one, which explicitly converts the character string to a 此查询在逻辑上等价于以下查询,它将字符串显式转换为DATE data type:DATE数据类型:
SELECT orderid, custid, empid, orderdate
FROM Sales.Orders
WHERE orderdate = CAST('20160212' AS DATE);
Note that some character-string formats of date and time literals are language dependent, meaning that when you convert them to a date and time data type, SQL Server might interpret the value differently based on the language setting in effect in the session. 请注意,日期和时间文本的某些字符串格式与语言有关,这意味着当您将它们转换为日期和时间数据类型时,SQL Server可能会根据会话中有效的语言设置对值进行不同的解释。Each login defined by the database administrator has a default language associated with it, and unless it is changed explicitly, that language becomes the effective language in the session. 数据库管理员定义的每个登录名都有一个与之关联的默认语言,除非明确更改,否则该语言将成为会话中的有效语言。You can overwrite the default language in your session by using the 您可以使用SET LANGUAGE command, but this is generally not recommended because some aspects of the code might rely on the user's default language.SET LANGUAGE命令覆盖会话中的默认语言,但通常不建议这样做,因为代码的某些方面可能依赖于用户的默认语言。
The effective language in the session sets several language-related settings behind the scenes. 会话中的有效语言在幕后设置了几个与语言相关的设置。Among them is one called 其中一个名为DATEFORMAT, which determines how SQL Server interprets the literals you enter when they are converted from a character-string type to a date and time type. DATEFORMAT,它决定了当您输入的文本从字符串类型转换为日期和时间类型时,SQL Server如何解释这些文本。The DATEFORMAT setting is expressed as a combination of the characters d, m, and y. DATEFORMAT设置表示为字符d、m和y的组合。For example, the 例如,美国英语设置将us_english language setting sets the DATEFORMAT to mdy, whereas the British language setting sets the DATEFORMAT to dmy. DATEFORMAT设置为mdy,而英国语言设置将DATEFORMAT设置为dmy。You can override the 您可以使用DATEFORMAT setting in your session by using the SET DATEFORMAT command, but as mentioned earlier, changing language-related settings is generally not recommended.SET DATEFORMAT命令覆盖会话中的DATEFORMAT设置,但如前所述,通常不建议更改与语言相关的设置。
Consider, for example, the literal '02/12/2016'. 例如,考虑文字'02/12/2016'。SQL Server can interpret the date as either February 12, 2016 or December 2, 2016 when you convert this literal to one of the following types: 当您将此文本转换为以下类型之一时,SQL Server可以将日期解释为2016年2月12日或2016年12月2日:DATETIME, SMALLDATETIME, DATE, DATETIME2, or DATETIMEOFFSET. DATETIME、SMALLDATETIME、DATE、DATETIME2或DATETIMEOFFSET。The effective 有效的“语言”/“日期格式”设置是决定因素。LANGUAGE/DATEFORMAT setting is the determining factor. To demonstrate different interpretations of the same character-string literal, run the following code:要演示对同一字符串文字的不同解释,请运行以下代码:
SET LANGUAGE British;
SELECT CAST('02/12/2016' AS DATE);
SET LANGUAGE us_english;
SELECT CAST('02/12/2016' AS DATE);
Notice in the output that the literal was interpreted differently in the two different language environments:请注意,在输出中,文字在两种不同的语言环境中的解释是不同的:
Changed language setting to British.
----------
2016-12-02
Changed language setting to us_english.
----------
2016-02-12
Note that the 请注意,“语言”/“日期格式”设置仅影响您输入的值的解释方式;这些设置对用于演示目的的输出中使用的格式没有影响。LANGUAGE/DATEFORMAT setting affects only the way the values you enter are interpreted; these settings have no impact on the format used in the output for presentation purposes. Output format is determined by the database interface used by the client tool (such as ODBC) and not by the 输出格式由客户端工具(如ODBC)使用的数据库接口决定,而不是由“语言”/“日期格式”设置决定。LANGUAGE/DATEFORMAT setting. For example, OLE DB and ODBC present 例如,OLE DB和ODBC以DATE values in the format 'YYYY-MM-DD'.'YYYY-MM-DD'格式显示DATE值。
Because the code you write might end up being used by international users with different language settings for their logins, understanding that some formats of literals are language dependent is crucial. 由于您编写的代码最终可能会被具有不同语言设置的国际用户用于登录,因此了解某些文本格式与语言有关至关重要。It is strongly recommended that you phrase your literals in a language-neutral manner. 强烈建议您以语言中立的方式表达文字。Language-neutral formats are always interpreted by SQL Server the same way and are not affected by language-related settings.SQL Server始终以相同的方式解释与语言无关的格式,并且不受与语言相关的设置的影响。
Table 2-2 provides literal formats that are considered neutral for each of the date and time types.Table 2-2提供了每种日期和时间类型被认为是中性的文本格式。
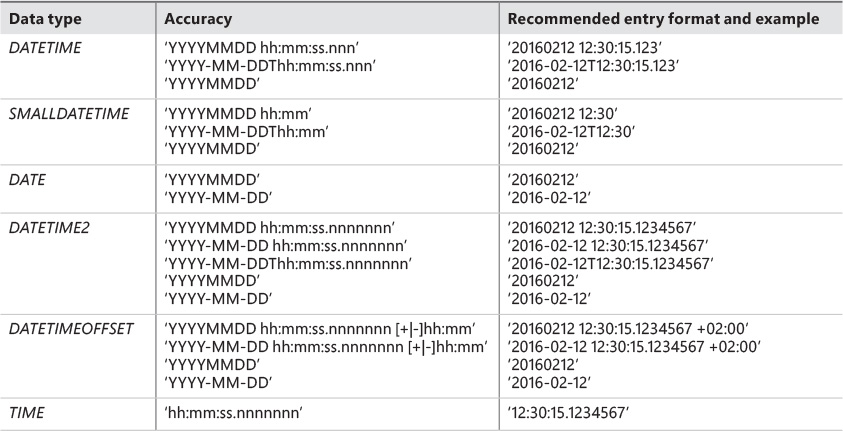
TABLE 2-2 Language-neutral date and time data type formats与语言无关的日期和时间数据类型格式
Note a couple of things about Table 2-2. 注意关于Table 2-2的几点。With all types that include both date and time components, if you don't specify a time part in your literal, SQL Server assumes midnight. 对于同时包含日期和时间组件的所有类型,如果不在文本中指定时间部分,SQL Server将假定为午夜。If you don't specify an offset from UTC, SQL Server assumes 00:00. 如果未指定UTC的偏移量,SQL Server将假定为00:00。Also note that the formats 'YYYY-MM-DD' and 'YYYY-MM-DD hh:mm...' are language dependent when converted to 还要注意的是格式DATETIME or SMALLDATETIME and language neutral when converted to DATE, DATETIME2, and DATETIMEOFFSET.'YYYY-MM-DD'和'YYYY-MM-DD hh:mm...'转换为DATETIME或SMALLDATETIME时与语言相关,转换为DATE、DATETIME2和DATETIMEOFFSET时与语言无关。
For example, notice in the following code that the language setting has no impact on how a literal expressed with the format 'YYYYMMDD' is interpreted when it is converted to 例如,请注意,在以下代码中,语言设置对格式为DATE:'YYYYMMDD'的文字在转换为日期时的解释方式没有影响:
SET LANGUAGE British;
SELECT CAST('20160212' AS DATE);
SET LANGUAGE us_english;
SELECT CAST('20160212' AS DATE);
The output shows that the literal was interpreted in both cases as February 12, 2016:输出显示,这两种情况下的文字解释为2016年2月12日:
Changed language setting to British.
----------
2016-02-12
Changed language setting to us_english.
----------
2016-02-12
I probably can't emphasize enough that using language-neutral formats such as 'YYYYMMDD' is a best practice, because such formats are interpreted the same way regardless of the 我可能再怎么强调也不为过,使用与语言无关的格式(如LANGUAGE/DATEFORMAT settings.'YYYYMMDD')是一种最佳实践,因为无论“语言”/“日期格式”设置如何,这些格式的解释方式都是相同的。
If you insist on using a language-dependent format to express literals, there are two options available to you. 如果您坚持使用依赖于语言的格式来表达文字,那么有两种选择可供选择。One is to use the 一种是使用CONVERT function to explicitly convert the character-string literal to the requested data type and, in the third argument, specify a number representing the style you used. CONVERT函数将字符串文本显式转换为请求的数据类型,并在第三个参数中指定一个表示所用样式的数字。SQL Server Books Online has a table with all the style numbers and the formats they represent. SQL Server联机手册有一个表,其中包含所有样式编号及其表示的格式。You can find it under the topic “The 您可以在主题“CAST and CONVERT Functions.” CAST和CONVERT函数”下找到它For example, if you want to specify the literal '02/12/2016' with the format 例如,如果要使用格式MM/DD/YYYY, use style number 101, as shown here:MM/DD/YYYY指定文字'02/12/2016',请使用样式号101,如下所示:
SELECT CONVERT(DATE, '02/12/2016', 101);
The literal is interpreted as February 12, 2016, regardless of the language setting that is in effect.无论现行语言设置如何,文字解释为2016年2月12日。
If you want to use the format 如果要使用DD/MM/YYYY, use style number 103:DD/MM/YYYY格式,请使用样式编号103:
SELECT CONVERT(DATE, '02/12/2016', 103);
This time, the literal is interpreted as December 2, 2016.这一次,字面解释为2016年12月2日。
Another option is to use the 另一个选项是使用PARSE function. PARSE函数。By using this function, you can parse a value as a requested type and indicate the culture. 通过使用此函数,可以将值解析为请求的类型并指示区域性。For example, the following is the equivalent of using 例如,以下内容相当于用样式101使用CONVERT with style 101 (US English):CONVERT(美式英语):
SELECT PARSE('02/12/2016' AS DATE USING 'en-US');
The following is equivalent to using 以下内容相当于用样式103使用CONVERT with style 103 (British English):CONVERT(英式英语):
SELECT PARSE('02/12/2016' AS DATE USING 'en-GB');
Note
The PARSE function is significantly more expensive than the CONVERT function; therefore, it is generally recommended you refrain from using it.PARSE函数比CONVERT函数要昂贵得多;因此,一般建议您不要使用它。
If you need to work with only dates or only times, it's recommended that you use the 如果只需要处理日期或时间,建议分别使用DATE and TIME data types, respectively. DATE和TIME数据类型。Adhering to this guideline can become challenging if you need to restrict yourself to using only the legacy types 如果出于与较旧系统的兼容性等原因,需要限制自己仅使用遗留类型DATETIME and SMALLDATETIME for reasons such as compatibility with older systems. DATETIME和SMALLDATETIME,那么遵守此准则可能会变得很有挑战性。The challenge is that the legacy types contain both the date and time components. 挑战在于遗留类型同时包含日期和时间组件。The best practice in such a case says that when you want to work only with dates, you store the date with a value of midnight in the time part. 这种情况下的最佳实践是,如果只想处理日期,则在时间部分存储值为午夜的日期。When you want to work only with times, you store the time with the base date January 1, 1900.如果只想使用时间,可以使用基准日期1900年1月1日存储时间。
To demonstrate working with date and time separately, I'll use a table called 为了演示如何分别处理日期和时间,我将使用一个名为Sales.Orders2, which has a column called orderdate of a DATETIME data type. Sales.Orders2的表,它有一个名为orderdate的列,属于DATETIME数据类型。Run the following code to create the 通过从Sales.Orders2 table by copying data from the Sales.Orders table and casting the source orderdate column, which is of a DATE type, to DATETIME:Sales.Orders表复制数据并将DATE类型的源orderdate列强制转换为DATETIME,运行以下代码来创建Sales.Orders2表:
DROP TABLE IF EXISTS Sales.Orders2;
SELECT orderid, custid, empid, CAST(orderdate AS DATETIME) AS orderdate
INTO Sales.Orders2
FROM Sales.Orders;
Don't worry if you're not familiar yet with the 如果您还不熟悉SELECT INTO statement. SELECT INTO语句,请不要担心。I describe it in Chapter 8, “Data modifications.”我在第8章“数据修改”中对此进行了描述
As mentioned, the 如前所述,orderdate column in the Sales.Orders2 table is of a DATETIME data type, but because only the date component is actually relevant, all values contain midnight as the time. Sales.Orders2表中的orderdate列是DATETIME数据类型,但因为只有日期组件是实际相关的,所以所有值都包含午夜作为时间组件。When you need to filter only orders from a certain date, you don't have to use a range filter. 如果只需要筛选某个日期的订单,则不必使用范围筛选器。Instead, you can use the equality operator like this:相反,可以像这样使用相等运算符:
SELECT orderid, custid, empid, orderdate
FROM Sales.Orders2
WHERE orderdate = '20160212';
When SQL Server converts a character-string literal that has only a date to 当SQL Server将只有日期的字符串文字转换为DATETIME, it assumes midnight by default. DATETIME时,默认情况下它假定为午夜。Because all values in the 由于orderdate column contain midnight in the time component, all orders placed on the requested date will be returned. orderdate列中的所有值在时间组件中都包含午夜,因此将返回在请求日期下的所有订单。Note that you can use a 请注意,可以使用CHECK constraint to ensure that only midnight is used as the time part:CHECK约束来确保只有午夜用作时间部分:
ALTER TABLE Sales.Orders2
ADD CONSTRAINT CHK_Orders2_orderdate
CHECK( CONVERT(CHAR(12), orderdate, 114) = '00:00:00:000' );
The CONVERT function extracts the time-only portion of the orderdate value as a character string using style 114. CONVERT函数使用样式114将orderdate值的仅时间部分提取为字符串。The CHECK constraint verifies that the string represents midnight.CHECK约束验证字符串是否表示午夜。
If the time component is stored with nonmidnight values, you can use a range filter like this:如果时间分量存储为非中间值,则可以使用如下范围筛选器:
SELECT orderid, custid, empid, orderdate
FROM Sales.Orders2
WHERE orderdate >= '20160212'
AND orderdate < '20160213';
If you want to work only with times using the legacy types, you can store all values with the base date of January 1, 1900. 如果只想使用遗留类型处理时间,可以存储基准日期为1900年1月1日的所有值。When SQL Server converts a character-string literal that contains only a time component to 当SQL Server将仅包含时间组件的字符串文字转换为DATETIME or SMALLDATETIME, SQL Server assumes that the date is the base date. DATETIME或SMALLDATETIME时,SQL Server假定该日期为基准日期。For example, run the following code:例如,运行以下代码:
SELECT CAST('12:30:15.123' AS DATETIME);
You get the following output:您将获得以下输出:
-----------------------
1900-01-01 12:30:15.123
Suppose you have a table with a column called 假设您有一个表,其中有一个名为tm of a DATETIME data type and you store all values by using the base date. tm的列,属于DATETIME数据类型,并且使用基准日期存储所有值。Again, this can be enforced with a 同样,这可以通过CHECK constraint. CHECK约束来强制执行。To return all rows for which the time value is 12:30:15.123, you use the filter 要返回时间值为12:30:15.123的所有行,请使用筛选器WHERE tm = '12:30:15.123'. WHERE tm='12:30:15.123'。Because you did not specify a date component, SQL Server assumes the date is the base date when it implicitly converts the character string to a 由于没有指定日期组件,SQL Server在隐式地将字符串转换为DATETIME data type.DATETIME数据类型时,会假定日期是基准日期。
If you want to work only with dates or only with times using the legacy types, but the input values you get include both date and time components, you need to apply some manipulation to the input values to “zero” the irrelevant part. 如果只想使用遗留类型处理日期或时间,但得到的输入值同时包含日期和时间组件,则需要对输入值进行一些操作,将不相关的部分“置零”。That is, set the time component to midnight if you want to work only with dates, and set the date component to the base date if you want to work only with times. 也就是说,如果只想处理日期,请将时间组件设置为午夜;如果只想处理时间,请将日期组件设置为基准日期。I'll explain how you can achieve this shortly, in the “Date and Time functions” section.我将在“日期和时间函数”部分简要介绍如何实现这一点。
Run the following code for cleanup:运行以下代码进行清理:
DROP TABLE IF EXISTS Sales.Orders2;
When you need to filter a range of dates, such as a whole year or a whole month, it seems natural to use functions such as 当你需要筛选一系列的日期时,比如一整年或者一整月,使用诸如YEAR and MONTH. YEAR和MONTH之类的函数似乎很自然。For example, the following query returns all orders placed in the year 2015:例如,以下查询返回2015年的所有订单:
SELECT orderid, custid, empid, orderdate
FROM Sales.Orders
WHERE YEAR(orderdate) = 2015;
However, you should be aware that in most cases, when you apply manipulation on the filtered column, SQL Server cannot use an index in an efficient manner. 但是,您应该知道,在大多数情况下,当您对筛选列应用操作时,SQL Server无法高效地使用索引。This is probably hard to understand without some background about indexes and performance, which are outside the scope of this book. 如果没有索引和性能方面的背景知识,这可能很难理解,这超出了本书的范围。For now, just keep this general point in mind: To have the potential to use an index efficiently, you shouldn't manipulate the filtered column. 现在,只需记住这一点:为了有可能有效地使用索引,不应该操纵筛选列。To achieve this, you can revise the filter predicate from the last query like this:要实现这一点,您可以修改上一个查询中的筛选谓词,如下所示:
SELECT orderid, custid, empid, orderdate
FROM Sales.Orders
WHERE orderdate >= '20150101' AND orderdate < '20160101';
Similarly, instead of using functions to filter orders placed in a particular month, like this:类似地,不要使用函数来筛选在特定月份下的订单,例如:
SELECT orderid, custid, empid, orderdate
FROM Sales.Orders
WHERE YEAR(orderdate) = 2016 AND MONTH(orderdate) = 2;
use a range filter, like the following:使用范围筛选器,如下所示:
SELECT orderid, custid, empid, orderdate
FROM Sales.Orders
WHERE orderdate >= '20160201' AND orderdate < '20160301';
In this section, I describe functions that operate on date and time data types, including 在本节中,我将介绍对日期和时间数据类型进行操作的函数,包括GETDATE, CURRENT_TIMESTAMP, GETUTCDATE, SYSDATETIME, SYSUTCDATETIME, SYSDATETIMEOFFSET, CAST, CONVERT, SWITCHOFFSET, AT TIME ZONE, TODATETIMEOFFSET, DATEADD, DATEDIFF and DATEDIFF_BIG, DATEPART, YEAR, MONTH, DAY, DATENAME, various FROMPARTS functions, and EOMONTH.GETDATE、CURRENT_TIMESTAMP、GETUTCDATE、SYSDATETIME、SYSUTCDATETIME、SYSDATETIMEOFFSET、CAST、CONVERT、SWITCHOFFSET、AT TIME ZONE、TODATETIMEOFFSET、DATEADD、DATEDIFF和DATEDIFF_BIG、DATEPART、YEAR、MONTH、DATENAME、各种FROMPARTS函数和EOMONTH。
The following 以下niladic (parameterless) functions return the current date and time values in the system where the SQL Server instance resides: GETDATE, CURRENT_TIMESTAMP, GETUTCDATE, SYSDATETIME, SYSUTCDATETIME, and SYSDATETIMEOFFSET.niladic(无参数)函数返回SQL Server实例所在系统中的当前日期和时间值:GETDATE、CURRENT_TIMESTAMP、GETUTCDATE、SYSDATETIME、SYSUTCDATETIME和SYSDATETIMEOFFSET。
Table 2-3 provides the description of these functions.Table 2-3提供了这些功能的说明。
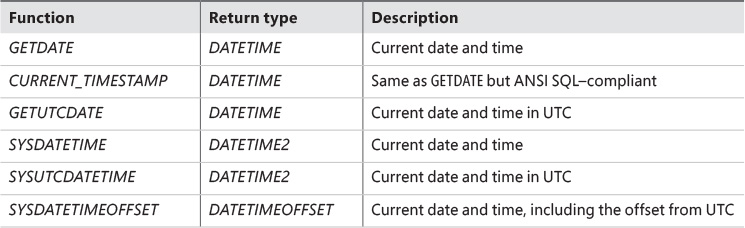
TABLE 2-3 Functions returning current date and time返回当前日期和时间的函数
Note that you need to specify empty parentheses with all functions that should be specified without parameters, except the standard function 注意,除了标准函数CURRENT_TIMESTAMP. CURRENT_TIMESTAMP之外,您需要为所有不带参数的函数指定空括号。Also, because 此外,由于CURRENT_TIMESTAMP and GETDATE return the same thing but only the former is standard, it is recommended that you use the former. CURRENT_TIMESTAMP和GETDATE返回相同的内容,但只有前者是标准的,因此建议使用前者。This is a practice I try to follow in general—when I have several options that do the same thing with no functional or performance difference, and one is standard but others aren't, my preference is to use the standard option.这是我通常尝试遵循的一种做法,当我有几个选项可以做相同的事情,没有功能或性能差异,其中一个是标准的,而其他不是,我的首选是使用标准选项。
The following code demonstrates using the current date and time functions:以下代码演示如何使用当前日期和时间函数:
SELECT
GETDATE() AS [GETDATE],
CURRENT_TIMESTAMP AS [CURRENT_TIMESTAMP],
GETUTCDATE() AS [GETUTCDATE],
SYSDATETIME() AS [SYSDATETIME],
SYSUTCDATETIME() AS [SYSUTCDATETIME],
SYSDATETIMEOFFSET() AS [SYSDATETIMEOFFSET];
As you probably noticed, none of the functions return only the current system date or only the current system time. 正如您可能注意到的,没有一个函数只返回当前系统日期或当前系统时间。However, you can get those easily by converting 但是,通过将CURRENT_TIMESTAMP or SYSDATETIME to DATE or TIME like this:CURRENT_TIMESTAMP或SYSDATETIME转换为如下DATE或TIME,您可以轻松获得这些信息:
SELECT
CAST(SYSDATETIME() AS DATE) AS [current_date],
CAST(SYSDATETIME() AS TIME) AS [current_time];
CAST, CONVERT, and PARSE functions and their TRY_ counterpartsCAST、CONVERT和PARSE函数以及它们的TRY_配对函数The CAST, CONVERT, and PARSE functions are used to convert an input value to some target type. CAST、CONVERT和PARSE函数用于将输入值转换为某种目标类型。If the conversion succeeds, the functions return the converted value; otherwise, they cause the query to fail. 如果转换成功,函数返回转换后的值;否则,它们会导致查询失败。The three functions have counterparts called 这三个函数分别称为TRY_CAST, TRY_CONVERT, and TRY_PARSE, respectively. TRY_CAST、TRY_CONVERT和TRY_PARSE。Each version with the prefix TRY_ accepts the same input as its counterpart and applies the same conversion; the difference is that if the input isn't convertible to the target type, the function returns a 前缀为NULL instead of failing the query.TRY_的每个版本接受与其对应版本相同的输入,并应用相同的转换;不同之处在于,如果输入不能转换为目标类型,函数将返回NULL,而不是查询失败。
CAST(value AS datatype)
TRY_CAST(value AS datatype)
CONVERT (datatype, value [, style_number])
TRY_CONVERT (datatype, value [, style_number])
PARSE (value AS datatype [USING culture])
TRY_PARSE (value AS datatype [USING culture])
All three base functions convert the input 所有三个基函数都将输入值转换为指定的目标数据类型。value to the specified target datatype. In some cases, 在某些情况下,CONVERT has a third argument with which you can specify the style of the conversion. CONVERT有第三个参数,您可以使用它指定转换的样式。For example, when you are converting from a character string to one of the date and time data types (or the other way around), the style number indicates the format of the string. 例如,当从字符串转换为日期和时间数据类型之一(或相反)时,样式号指示字符串的格式。For example, style 101 indicates 'MM/DD/YYYY', and style 103 indicates 'DD/MM/YYYY'. 例如,样式101表示'MM/DD/YYYY',样式103表示'DD/MM/YYYY'。You can find the full list of style numbers and their meanings in SQL Server Books Online under “您可以在SQL Server联机丛书的“CAST and CONVERT.” CAST和CONVERT”下找到样式号及其含义的完整列表Similarly, where applicable, the 类似地,在适用的情况下,PARSE function supports the indication of a culture—for example, 'en-US' for U.S. English and 'en-GB' for British English.PARSE函数支持一种文化的指示,例如“en-US”表示美式英语,“en-GB”表示英式英语。
As mentioned earlier, when you are converting from a character string to one of the date and time data types, some of the string formats are language dependent. 如前所述,当您从字符串转换为日期和时间数据类型时,某些字符串格式与语言有关。I recommend either using one of the language-neutral formats or using the 我建议使用一种与语言无关的格式,或者使用CONVERT function and explicitly specifying the style number. CONVERT函数并显式指定样式号。This way, your code is interpreted the same way regardless of the language of the login running it.这样,无论运行代码的登录名使用何种语言,代码的解释方式都是相同的。
Note that 请注意,CAST is standard and CONVERT and PARSE aren't, so unless you need to use the style number or culture, it is recommended that you use the CAST function.CAST是标准的,而CONVERT和PARSE不是,因此除非您需要使用样式号或区域性,否则建议您使用CAST函数。
Following are a few examples of using the 下面是一些使用日期和时间数据类型的CAST, CONVERT, and PARSE functions with date and time data types. CAST、CONVERT和PARSE函数的示例。The following code converts the character string literal '20160212' to a 以下代码将字符串文字DATE data type:'20160212'转换为DATE数据类型:
SELECT CAST('20160212' AS DATE);
The following code converts the current system date and time value to a 以下代码将当前系统日期和时间值转换为DATE data type, practically extracting only the current system date:DATE数据类型,实际上只提取当前系统日期:
SELECT CAST(SYSDATETIME() AS DATE);
The following code converts the current system date and time value to a 以下代码将当前系统日期和时间值转换为TIME data type, practically extracting only the current system time:TIME数据类型,实际上只提取当前系统时间:
SELECT CAST(SYSDATETIME() AS TIME);
As suggested earlier, if you need to work with the 如前所述,如果需要使用DATETIME or SMALLEDATETIME types (for example, to be compatible with legacy systems) and want to represent only a date or only a time, you can set the irrelevant part to a specific value. DATETIME或SMALLEDATETIME类型(例如,为了与传统系统兼容),并且只想表示一个日期或一个时间,可以将不相关的部分设置为特定的值。To work only with dates, you set the time to midnight. 要仅处理日期,请将时间设置为午夜。To work only with time, you set the date to the base date January 1, 1900.要仅使用时间,请将日期设置为基准日期1900年1月1日。
The following code converts the current date and time value to 以下代码使用样式112(CHAR(8) by using style 112 ('YYYYMMDD'):'YYYYMMDD')将当前日期和时间值转换为CHAR(8):
SELECT CONVERT(CHAR(8), CURRENT_TIMESTAMP, 112);
For example, if the current date is February 12, 2016, this code returns '20160212'. 例如,如果当前日期是2016年2月12日,则此代码返回'20160212'。You then convert the character string back to 然后将字符串转换回DATETIME and get the current date at midnight:DATETIME,并在午夜获取当前日期:
SELECT CONVERT(DATETIME, CONVERT(CHAR(8), CURRENT_TIMESTAMP, 112), 112);
Similarly, to zero the date portion to the base date, you can first convert the current date and time value to 类似地,要将日期部分归零为基准日期,可以首先使用样式114(CHAR(12) by using style 114 ('hh:mm:ss.nnn'):'hh:mm:ss.nnn')将当前日期和时间值转换为CHAR(12):
SELECT CONVERT(CHAR(12), CURRENT_TIMESTAMP, 114);
When the code is converted back to 当代码转换回DATETIME, you get the current time on the base date:DATETIME时,您将获得基准日期的当前时间:
SELECT CONVERT(DATETIME, CONVERT(CHAR(12), CURRENT_TIMESTAMP, 114), 114);
As for using the 关于使用PARSE function, here are a couple of examples:PARSE函数,这里有几个例子:
SELECT PARSE('02/12/2016' AS DATETIME USING 'en-US');
SELECT PARSE('02/12/2016' AS DATETIME USING 'en-GB');
The first example parses the input string by using a U.S. English culture, and the second one does so by using a British English culture.第一个示例使用美式英语解析输入字符串,而第二种是通过使用英式英语来实现的。
As a reminder, the 提醒一下,PARSE function is significantly more expensive than the CONVERT function; therefore, I recommend you use the latter.PARSE函数比CONVERT函数要昂贵得多;因此,我建议你使用后者。
SWITCHOFFSET functionSWITCHOFFSET函数The SWITCHOFFSET function adjusts an input DATETIMEOFFSET value to a specified target offset from UTC.SWITCHOFFSET函数将输入的DATETIMEOFFSET值调整为与UTC的指定目标偏移量。
SWITCHOFFSET(datetimeoffset_value, UTC_offset)
For example, the following code adjusts the current system 例如,以下代码将当前系统datetimeoffset value to offset –05:00.datetimeoffset值调整为offse t-05:00。
SELECT SWITCHOFFSET(SYSDATETIMEOFFSET(), '-05:00');
So if the current system 因此,如果当前系统datetimeoffset value is February 12, 2016 10:00:00.0000000 –08:00, this code returns the value February 12, 2016 13:00:00.0000000 –05:00.datetimeoffset值为2016年2月12日10:00:00.0000000 -08:00,则此代码返回值2016年2月12日13:00:00.0000000 -05:00。
The following code adjusts the current 以下代码将当前datetimeoffset value to UTC:datetimeoffset值调整为UTC:
SELECT SWITCHOFFSET(SYSDATETIMEOFFSET(), '+00:00');
Assuming the aforementioned current 假设前面提到的当前datetimeoffset value, this code returns the value February 12, 2016 18:00:00.0000000 +00:00.datetimeoffset值,此代码返回值2016年2月12日18:00:00.0000000+00:00。
TODATETIMEOFFSET functionTODATETIMEOFFSET函数The TODATETIMEOFFSET function constructs a DATETIMEOFFSET typed value from a local date and time value and an offset from UTC.TODATETIMEOFFSET函数根据本地日期和时间值以及UTC偏移量构造DATETIMEOFFSET类型的值。
TODATETIMEOFFSET(local_date_and_time_value, UTC_offset)
This function is different from 此函数不同于SWITCHOFFSET in that its first input is a local date and time value without an offset component. SWITCHOFFSET,因为它的第一个输入是一个本地日期和时间值,没有偏移分量。This function simply merges the input date and time value with the specified offset to create a new 此函数只需将输入的日期和时间值与指定的偏移量合并,即可创建新的datetimeoffset value.datetimeoffset值。
You will typically use this function when migrating non-offset-aware data to offset-aware data. 在将非偏移感知数据迁移到偏移感知数据时,通常会使用此函数。Imagine you have a table holding local date and time values in an attribute called 假设您有一个表,在一个名为dt of a DATETIME2 or DATETIME data type and holding the offset in an attribute called theoffset. dt的属性中保存本地日期和时间值,该属性是DATETIME2或DATETIME数据类型,在一个名为theoffset的属性中保存偏移量。You then decide to merge the two to one offset-aware attribute called 然后决定将名为dto. dto的两对一偏移感知属性合并。You alter the table and add the new attribute. 更改表并添加新属性。Then you update it to the result of the expression 然后将其更新为TODATETIMEOFFSET(dt, theoffset). TODATETIMEOFFSET(dt, theoffset)表达式的结果。Then you can drop the two existing attributes 然后可以删除现有的两个属性dt and theoffset.dt和theoffset。
AT TIME ZONE functionAT TIME ZONE函数The AT TIME ZONE function accepts an input date and time value and converts it to a datetimeoffset value that corresponds to the specified target time zone. AT TIME ZONE函数接受输入日期和时间值,并将其转换为与指定目标时区相对应的datetimeoffset值。This function was introduced in SQL Server 2016.SQL Server 2016中引入了此功能。
dt_val AT TIME ZONE time_zone
The input 输入dt_val can be of the following data types: DATETIME, SMALLDATETIME, DATETIME2, and DATETIMEOFFSET. dt_val可以是以下数据类型:DATETIME、SMALLDATETIME、DATETIME2和DATETIMEOFFSET。The input 输入time_zone can be any of the supported Windows time-zone names as they appear in the name column in the sys.time_zone_info view. time_zone可以是任何受支持的Windows时区名称,它们出现在sys.time_zone_info视图的name列中。Use the following query to see the available time zones, their current offset from UTC and whether it's currently Daylight Savings Time (DST):使用以下查询查看可用时区、它们与UTC的当前偏移以及当前是否为夏令时(DST):
SELECT name, current_utc_offset, is_currently_dst
FROM sys.time_zone_info;
Regarding 关于dt_val: when using any of the three non-datetimeoffset types (DATETIME, SMALLDATETIME, and DATETIME2), the AT TIME ZONE function assumes the input value is already in the target time zone. dt_val:当使用三种非datetimeoffset类型(DATETIME、SMALLDATETIME和DATETIME2)中的任何一种时,AT TIME ZONE函数假定输入值已经在目标时区中。As a result, it behaves similar to the 因此,它的行为类似于TODATETIMEOFFSET function, except the offset isn't necessarily fixed. TODATETIMEOFFSET函数,只是偏移量不一定是固定的。It depends on whether DST applies. 这取决于DST是否适用。Take the time zone Pacific Standard Time as an example. 以时区太平洋标准时间为例。When it's not DST, the offset from UTC is –08:00; when it is DST, the offset is –07:00. 如果不是DST,则与UTC的偏移量为-08:00;当为DST时,偏移量为-07:00。The following code demonstrates the use of this function with non-以下代码演示了在非datetimeoffset inputs:datetimeoffset输入中使用此函数:
SELECT
CAST('20160212 12:00:00.0000000' AS DATETIME2)
AT TIME ZONE 'Pacific Standard Time' AS val1,
CAST('20160812 12:00:00.0000000' AS DATETIME2)
AT TIME ZONE 'Pacific Standard Time' AS val2;
This code generates the following output:此代码生成以下输出:
val1 val2
---------------------------------- ----------------------------------
2016-02-12 12:00:00.0000000 -08:00 2016-08-12 12:00:00.0000000 -07:00
The first value happens when DST doesn't apply; hence, offset –08:00 is assumed. 第一个值发生在DST不适用时;因此,假定偏移量为-08:00。The second value happens during DST; hence, offset –07:00 is assumed. Here there's no ambiguity.第二个值发生在DST期间;因此,假定偏移量为-07:00。这里没有歧义。
There are two tricky cases: when switching to DST and when switching from DST. 有两种棘手的情况:切换到DST和从DST切换。For example, in Pacific Standard Time, when switching to DST the clock is advanced by an hour, so there's an hour that doesn't exist. 例如,在太平洋标准时间,当切换到DST时,时钟会提前一个小时,所以有一个小时是不存在的。If you specify a nonexisting time during that hour, the offset before the change (–08:00) is assumed. 如果指定该小时内不存在的时间,则假定更改前的偏移量(-08:00)。When switching from DST, the clock retreats by an hour, so there's an hour that repeats itself. 当从DST切换时,时钟会后退一小时,所以有一个小时会自动重复。If you specify a time during that hour, starting at the bottom of the hour, non-DST is assumed (that is, the offset –08:00 is used).如果在该小时内指定一个时间,从该小时的底部开始,则假定为非DST(即使用偏移量-08:00)。
When the input 当输入dt_val is a datetimeoffset value, the AT TIME ZONE function behaves more similarly to the SWITCHOFFSET function. dt_val是datetimeoffset值时,AT TIME ZONE函数的行为与SWITCHOFFSET函数更相似。Again, however, the target offset isn't necessarily fixed. 然而,目标偏移量也不一定是固定的。T-SQL uses the Windows time-zone-conversion rules to apply the conversion. T-SQL使用Windows时区转换规则应用转换。The following code demonstrates the use of the function with 以下代码演示如何使用带有datetimeoffset inputs:datetimeoffset输入的函数:
SELECT
CAST('20160212 12:00:00.0000000 -05:00' AS DATETIMEOFFSET)
AT TIME ZONE 'Pacific Standard Time' AS val1,
CAST('20160812 12:00:00.0000000 -04:00' AS DATETIMEOFFSET)
AT TIME ZONE 'Pacific Standard Time' AS val2;
The input values reflect the time zone Eastern Standard Time. 输入值反映时区东部标准时间。Both have noon in the time component. 两者都有时间成分中的正午。The first value occurs when DST doesn't apply (offset is –05:00), and the second one occurs when DST does apply (that is, the offset is –04:00). 第一个值出现在DST不适用时(偏移量为-05:00),第二个值出现在DST确实适用时(即偏移量为-04:00)。Both values are converted to the time zone Pacific Standard Time (the offset –08:00 when DST doesn't apply and –07:00 when it does). 这两个值都转换为时区太平洋标准时间(DST不适用时偏移量为-08:00,DST适用时偏移量为-07:00)。In both cases, the time needs to retreat by three hours to 9:00 AM. 在这两种情况下,时间都需要缩短三个小时至上午9点。You get the following output:您将获得以下输出:
val1 val2
---------------------------------- ----------------------------------
2016-02-12 09:00:00.0000000 -08:00 2016-08-12 09:00:00.0000000 -07:00
DATEADD functionDATEADD函数You use the 可以使用DATEADD function to add a specified number of units of a specified date part to an input date and time value.DATEADD函数将指定日期部分的指定数量的单位添加到输入日期和时间值中。
DATEADD(part, n, dt_val)
Valid values for the part input include year, quarter, month, dayofyear, day, week, weekday, hour, minute, second, millisecond, microsecond, and nanosecond. part输入的有效值包括year、quarter、month、dayofyear、day、week、weekday、hour、minute、second、millisecond、microsecond和nanosecond。You can also specify the part in abbreviated form, such as 您还可以用缩写形式指定yy instead of year. part,例如yy而不是year。Refer to SQL Server Books Online for details.有关详细信息,请参阅SQL Server联机丛书。
The return type for a date and time input is the same type as the input's type. 日期和时间输入的返回类型与输入的类型相同。If this function is given a string literal as input, the output is 如果给这个函数一个字符串文本作为输入,那么输出是DATETIME.DATETIME。
For example, the following code adds one year to February 12, 2016:例如,以下代码将2016年2月12日延长一年:
SELECT DATEADD(year, 1, '20160212');
This code returns the following output:此代码返回以下输出:
-----------------------
2017-02-12 00:00:00.000
DATEDIFF and DATEDIFF_BIG FunctionsDATEDIFF和DATEDIFF_BIG函数The DATEDIFF and DATEDIFF_BIG functions return the difference between two date and time values in terms of a specified date part. DATEDIFF和DATEDIFF_BIG函数根据指定的日期部分返回两个日期和时间值之间的差值。The former returns a value typed as 前者返回类型为INT (a 4-byte integer), and the latter returns a value typed as BIGINT (an 8-byte integer). INT(4字节整数)的值,后者返回类型为BIGINT(8字节整数)的值。The function SQL Server 2016中引入了DATEDIFF_BIG was introduced in SQL Server 2016.DATEDIFF_BIG函数。
DATEDIFF(, part, dt_val1, dt_val2)DATEDIFF_BIG(part, dt_val1, dt_val2)
For example, the following code returns the difference in terms of days between two values:例如,以下代码返回两个值之间的天数差:
SELECT DATEDIFF(day, '20150212', '20160212');
This code returns the output 366.此代码返回输出366。
There are certain differences that result in an integer that is greater than the maximum INT value (2,147,483,647). 某些差异会导致整数大于最大整数值(2147483647)。For example, the difference in milliseconds between January 1, 0001 and February 12, 2016 is 63,590,832,000,000. 例如,0001年1月1日和2016年2月12日之间的毫秒差为635908320000。You can't use the 不能使用DATEDIFF function to compute such a difference, but you can achieve this with the DATEDIFF_BIG function:DATEDIFF函数来计算这样的差异,但可以使用DATEDIFF_BIG函数来实现这一点:
SELECT DATEDIFF_BIG(millisecond, '00010101', '20160212');
If you need to compute the beginning of the day that corresponds to an input date and time value, you can simply cast the input value to the 如果需要计算与输入日期和时间值对应的一天的开始时间,只需将输入值转换为DATE type and then cast the result to the target type. DATE类型,然后将结果转换为目标类型。But with a bit more sophisticated use of the 但是,通过更复杂地使用DATEADD and DATEDIFF functions, you can compute the beginning or end of different parts (day, month, quarter, year) that correspond to the input value. DATEADD和DATEDIFF函数,可以计算与输入值相对应的不同部分(日、月、季、年)的开始或结束。For example, use the following code to compute the beginning of the day that corresponds to the input date and time value:例如,使用以下代码计算与输入日期和时间值相对应的一天的开始时间:
SELECT
DATEADD(
day,
DATEDIFF(day, '19000101', SYSDATETIME()), '19000101');
This is achieved by first using the 这是通过首先使用DATEDIFF function to calculate the difference in terms of whole days between an anchor date at midnight ('19000101' in this case) and the current date and time (call that difference diff). DATEDIFF函数来计算午夜定位日期(本例中为19000101)与当前日期和时间(称之为差值diff)之间的整天差值来实现的。Then the 然后使用DATEADD function is used to add diff days to the anchor. DATEADD函数向锚添加不同的天数。You get the current system date at midnight.你会在午夜得到当前的系统日期。
If you use this expression with a month part instead of a day, and make sure to use an anchor that is the first day of a month (as in this example), you get the first day of the current month:如果将此表达式与月份部分(而不是日期)一起使用,并确保使用一个月的第一天作为锚点(如本例中所示),则会得到当前月份的第一天:
SELECT
DATEADD(
month,
DATEDIFF(month, '19000101', SYSDATETIME()), '19000101');
Similarly, by using a year part and an anchor that is the first day of a year, you get back the first day of the current year.类似地,通过使用一年的一部分和一年的第一天作为锚,可以返回当前一年的第一天。
If you want the last day of the month or year, simply use an anchor that is the last day of a month or year. 如果你想要一个月或一年的最后一天,只需使用一个月或一年的最后一天的锚。For example, the following expression returns the last day of the current year:例如,以下表达式返回当前年份的最后一天:
SELECT
DATEADD(
year,
DATEDIFF(year, '18991231', SYSDATETIME()), '18991231');
Using a similar expression with the month part, you can get the last day of the month, but it's much easier to achieve this using the function 使用与月份部分类似的表达式,可以得到月份的最后一天,但使用函数EOMONTH instead. EOMONTH更容易实现这一点。Unfortunately, there are no similar functions to get the end of quarter and year, so you will need to use a computation for those such as the one just shown.不幸的是,没有类似的函数来计算季度末和年度末,所以您需要对这些函数进行计算,比如刚才显示的函数。
DATEPART functionDATEPART函数The DATEPART function returns an integer representing a requested part of a date and time value.DATEPART函数返回一个整数,表示日期和时间值的请求部分。
DATEPART(part, dt_val)
Valid values for the part argument include year, quarter, month, dayofyear, day, week, weekday, hour, minute, second, millisecond, microsecond, nanosecond, TZoffset, and ISO_WEEK. part参数的有效值包括year、quarter、month、dayofyear、day、week、weekday、hour、minute、second、millisecond、microsecond、nanosecond、TZoffset和ISO_WEEK。As mentioned, you can use abbreviations for the date and time parts, such as 如前所述,日期和时间部分可以使用缩写,例如yy instead of year, mm instead of month, dd instead of day, and so on.yy代替year,mm代替month,dd代替day,等等。
For example, the following code returns the month part of the input value:例如,以下代码返回输入值的月份部分:
SELECT DATEPART(month, '20160212');
This code returns the integer 2.这段代码返回整数2。
YEAR, MONTH, and DAY functionsYEAR、MONTH和DAY函数The YEAR, MONTH, and DAY functions are abbreviations for the DATEPART function returning the integer representation of the year, month, and day parts of an input date and time value.YEAR、MONTH和DAY函数是DATEPART函数的缩写,该函数返回输入日期和时间值的年、月和日部分的整数表示形式。
YEAR(dt_val)
MONTH(dt_val)
DAY(dt_val)
For example, the following code extracts the day, month, and year parts of an input value:例如,以下代码提取输入值的日、月和年部分:
SELECT
DAY('20160212') AS theday,
MONTH('20160212') AS themonth,
YEAR('20160212') AS theyear;
This code returns the following output:此代码返回以下输出:
theday themonth theyear
----------- ----------- -----------
12 2 2016
DATENAME functionDATENAME函数The DATENAME function returns a character string representing a part of a date and time value.DATENAME函数返回一个字符串,表示日期和时间值的一部分。
DATENAME(dt_val, part)
This function is similar to 该函数类似于DATEPART and, in fact, has the same options for the part input. DATEPART,事实上,对于part输入具有相同的选项。However, when relevant, it returns the name of the requested part rather than the number. 但是,如果相关,它会返回请求部件的名称,而不是编号。For example, the following code returns the month name of the given input value:例如,以下代码返回给定输入值的月份名称:
SELECT DATENAME(month, '20160212');
Recall that 回想一下DATEPART returned the integer 2 for this input. DATEPART为此输入返回了整数2。DATENAME returns the name of the month, which is language dependent. DATENAME返回月份的名称,该名称与语言有关。If your session's language is one of the English languages (such as U.S. English or British English), you get back the value 'February'. 如果会话的语言是其中一种英语(如美式英语或英式英语),则返回值'February'。If your session's language is Italian, you get back the value 'febbraio'. 如果会话的语言是意大利语,则返回值“'febbraio'。If a part is requested that has no name, and only a numeric value (such as 如果请求的零件没有名称,只有一个数字值(如year), the DATENAME function returns its numeric value as a character string. year),DATENAME函数将以字符串形式返回其数字值。For example, the following code returns '2016':例如,以下代码返回'2016':
SELECT DATENAME(year, '20160212');
ISDATE functionISDATE函数The ISDATE function accepts a character string as input and returns 1 if it is convertible to a date and time data type and 0 if it isn't.ISDATE函数接受字符串作为输入,如果可以转换为日期和时间数据类型,则返回1;如果不能转换为日期和时间数据类型,则返回0。
ISDATE(string)
For example, the following code returns 1:例如,以下代码返回1:
SELECT ISDATE('20160212');
And the following code returns 0:下面的代码返回0:
SELECT ISDATE('20160230');
FROMPARTS functionsFROMPARTS函数The FROMPARTS functions accept integer inputs representing parts of a date and time value and construct a value of the requested type from those parts.FROMPARTS函数接受表示日期和时间值部分的整数输入,并从这些部分构造请求类型的值。
DATEFROMPARTS (year, month, day)
DATETIME2FROMPARTS (year, month, day, hour, minute, seconds, fractions, precision)
DATETIMEFROMPARTS (year, month, day, hour, minute, seconds, milliseconds)
DATETIMEOFFSETFROMPARTS (year, month, day, hour, minute, seconds, fractions, hour_offset, minute_offset, precision)
SMALLDATETIMEFROMPARTS (year, month, day, hour, minute)
TIMEFROMPARTS (hour, minute, seconds, fractions, precision)
These functions make it easier for programmers to construct date and time values from the different components, and they also simplify migrating code from other environments that already support similar functions. 这些函数使程序员更容易从不同的组件构造日期和时间值,并且它们还简化了从已经支持类似函数的其他环境迁移代码的过程。The following code demonstrates the use of these functions:以下代码演示了这些函数的使用:
SELECT
DATEFROMPARTS(2016, 02, 12),
DATETIME2FROMPARTS(2016, 02, 12, 13, 30, 5, 1, 7),
DATETIMEFROMPARTS(2016, 02, 12, 13, 30, 5, 997),
DATETIMEOFFSETFROMPARTS(2016, 02, 12, 13, 30, 5, 1, -8, 0, 7),
SMALLDATETIMEFROMPARTS(2016, 02, 12, 13, 30),
TIMEFROMPARTS(13, 30, 5, 1, 7);
EOMONTH functionEOMONTH函数The EOMONTH function accepts an input date and time value and returns the respective end-of-month date as a DATE typed value. EOMONTH函数接受输入的日期和时间值,并将相应的月末日期作为DATE类型的值返回。The function also supports an optional second argument indicating how many months to add (or subtract, if negative).该函数还支持一个可选的第二个参数,指示要加多少个月(如果是负数,则减去多少个月)。
EOMONTH(input [, months_to_add])
For example, the following code returns the end of the current month:例如,以下代码返回当前月底:
SELECT EOMONTH(SYSDATETIME());
The following query returns orders placed on the last day of the month:以下查询返回当月最后一天下的订单:
SELECT orderid, orderdate, custid, empid
FROM Sales.Orders
WHERE orderdate = EOMONTH(orderdate);
SQL Server provides tools for getting information about the metadata of objects, such as information about tables in a database and columns in a table. SQL Server提供了获取对象元数据信息的工具,例如数据库中表和表中列的信息。Those tools include catalog views, information schema views, and system stored procedures and functions. 这些工具包括目录视图、信息模式视图以及系统存储过程和函数。This area is documented well in SQL Server Books Online in the “Querying the SQL Server System Catalog” section, so I won't cover it in great detail here. SQL Server联机丛书中的“查询SQL Server系统目录”一节对这一领域进行了详细介绍,因此我在这里不详细介绍。I'll just give a couple of examples of each metadata tool to give you a sense of what's available and get you started.我将给出每个元数据工具的几个示例,让您了解可用的内容,并开始使用。
Catalog views provide detailed information about objects in the database, including information that is specific to SQL Server. 目录视图提供有关数据库中对象的详细信息,包括特定于SQL Server的信息。For example, if you want to list the tables in a database along with their schema names, you can query the 例如,如果要列出数据库中的表及其架构名称,可以按如下方式查询sys.tables view as follows:sys.tables视图:
USE TSQLV4;
SELECT SCHEMA_NAME(schema_id) AS table_schema_name, name AS table_name
FROM sys.tables;
The SCHEMA_NAME function is used to convert the schema ID integer to its name. SCHEMA_NAME函数用于将SCHEMA ID整数转换为其名称。This query returns the following output:此查询返回以下输出:
table_schema_name table_name
------------------ --------------
HR Employees
Production Suppliers
Production Categories
Production Products
Sales Customers
Sales Shippers
Sales Orders
Sales OrderDetails
Stats Tests
Stats Scores
dbo Nums
To get information about columns in a table, you can query the 要获取表中列的信息,可以查询sys.columns table. sys.columns表。For example, the following code returns information about columns in the 例如,以下代码返回有关Sales.Orders table, including column names, data types (with the system type ID translated to a name by using the TYPE_NAME function), maximum length, collation name, and nullability:Sales.Orders表中列的信息,包括列名、数据类型(使用TYPE_NAME函数将系统类型ID转换为名称)、最大长度、排序规则名称和可空性:
SELECT
name AS column_name,
TYPE_NAME(system_type_id) AS column_type,
max_length,
collation_name,
is_nullable
FROM sys.columns
WHERE object_id = OBJECT_ID(N'Sales.Orders');
This query returns the following output:此查询返回以下输出:
column_name column_type max_length collation_name is_nullable
--------------- ------------ ---------- --------------------- -----------
orderid int 4 NULL 0
custid int 4 NULL 1
empid int 4 NULL 0
orderdate date 3 NULL 0
requireddate date 3 NULL 0
shippeddate date 3 NULL 1
shipperid int 4 NULL 0
freight money 8 NULL 0
shipname nvarchar 80 Latin1_General_CI_AS 0
shipaddress nvarchar 120 Latin1_General_CI_AS 0
shipcity nvarchar 30 Latin1_General_CI_AS 0
shipregion nvarchar 30 Latin1_General_CI_AS 1
shippostalcode nvarchar 20 Latin1_General_CI_AS 1
shipcountry nvarchar 30 Latin1_General_CI_AS 0
An information schema view is a set of views that resides in a schema called 信息模式视图是一组视图,位于名为INFORMATION_SCHEMA and provides metadata information in a standard manner. INFORMATION_SCHEMA的模式中,并以标准方式提供元数据信息。That is, the views are defined in the SQL standard, so naturally they don't cover metadata aspects or objects specific to SQL Server (such as indexing).也就是说,视图是在SQL标准中定义的,因此它们自然不包括特定于SQL Server的元数据方面或对象(例如索引)。
For example, the following query against the 例如,以下针对INFORMATION_SCHEMA.TABLES view lists the user tables in the current database along with their schema names:INFORMATION_SCHEMA.TABLES视图的查询列出了当前数据库中的用户表及其模式名称:
SELECT TABLE_SCHEMA, TABLE_NAME
FROM INFORMATION_SCHEMA.TABLES
WHERE TABLE_TYPE = N'BASE TABLE';
The following query against the 以下针对INFORMATION_SCHEMA.COLUMNS view provides most of the available information about columns in the Sales.Orders table:INFORMATION_SCHEMA.COLUMNS视图的查询提供了有关Sales.Orders表中列的大部分可用信息:
SELECT
COLUMN_NAME, DATA_TYPE, CHARACTER_MAXIMUM_LENGTH,
COLLATION_NAME, IS_NULLABLE
FROM INFORMATION_SCHEMA.COLUMNS
WHERE TABLE_SCHEMA = N'Sales'
AND TABLE_NAME = N'Orders';
System stored procedures and functions internally query the system catalog and give you back more “digested” metadata information. 系统存储过程和函数在内部查询系统目录,并返回更多“摘要”元数据信息。Again, you can find the full list of objects and their detailed descriptions in SQL Server Books Online, but here are a few examples.同样,您可以在SQL Server联机丛书中找到对象的完整列表及其详细描述,但这里有几个示例。
The sp_tables stored procedure returns a list of objects (such as tables and views) that can be queried in the current database:sp_tables存储过程返回可在当前数据库中查询的对象(如表和视图)列表:
EXEC sys.sp_tables;
The sp_help procedure accepts an object name as input and returns multiple result sets with general information about the object, and also information about columns, indexes, constraints, and more. sp_help过程接受一个对象名作为输入,并返回多个结果集,其中包含有关该对象的一般信息,以及有关列、索引、约束等的信息。For example, the following code returns detailed information about the 例如,以下代码返回有关Orders table:Orders表的详细信息:
EXEC sys.sp_help
@objname = N'Sales.Orders';
The sp_columns procedure returns information about columns in an object. sp_columns过程返回有关对象中列的信息。For example, the following code returns information about columns in the 例如,以下代码返回有关Orders table:Orders表中列的信息:
EXEC sys.sp_columns
@table_name = N'Orders',
@table_owner = N'Sales';
The sp_helpconstraint procedure returns information about constraints in an object. sp_helpconstraint过程返回有关对象中约束的信息。For example, the following code returns information about constraints in the 例如,以下代码返回有关Orders table:Orders表中约束的信息:
EXEC sys.sp_helpconstraint
@objname = N'Sales.Orders';
One set of functions returns information about properties of entities such as the SQL Server instance, database, object, column, and so on. 一组函数返回有关实体属性的信息,如SQL Server实例、数据库、对象、列等。The SERVERPROPERTY function returns the requested property of the current instance. SERVERPROPERTY函数返回当前实例的请求属性。For example, the following code returns the product level (such as RTM, SP1, SP2, and so on) of the current instance:例如,以下代码返回当前实例的产品级别(如RTM、SP1、SP2等):
SELECT
SERVERPROPERTY('ProductLevel');
The DATABASEPROPERTYEX function returns the requested property of the specified database name. DATABASEPROPERTYEX函数返回指定数据库名称的请求属性。For example, the following code returns the collation of the TSQLV4 database:例如,以下代码返回TSQLV4数据库的排序规则:
SELECT
DATABASEPROPERTYEX(N'TSQLV4', 'Collation');
The OBJECTPROPERTY function returns the requested property of the specified object name. OBJECTPROPERTY函数返回指定对象名称的请求属性。For example, the output of the following code indicates whether the 例如,以下代码的输出指示Orders table has a primary key:Orders表是否有主键:
SELECT
OBJECTPROPERTY(OBJECT_ID(N'Sales.Orders'), 'TableHasPrimaryKey');
Notice the nesting of the function 注意OBJECT_ID within OBJECTPROPERTY. OBJECTPROPERTY中函数OBJECT_ID的嵌套。The OBJECTPROPERTY function expects an object ID and not a name, so the OBJECT_ID function is used to return the ID of the Orders table.OBJECTPROPERTY函数需要一个对象ID而不是名称,因此object_ID函数用于返回Orders表的ID。
The COLUMNPROPERTY function returns the requested property of a specified column. COLUMNPROPERTY函数返回指定列的请求属性。For example, the output of the following code indicates whether the 例如,以下代码的输出指示shipcountry column in the Orders table is nullable:Orders表中的shipcountry列是否可为空:
SELECT
COLUMNPROPERTY(OBJECT_ID(N'Sales.Orders'), N'shipcountry', 'AllowsNull');
This chapter introduced you to the 本章向您介绍了SELECT statement, logical query processing, and various other aspects of single-table queries. SELECT语句、逻辑查询处理以及单表查询的其他各个方面。I covered quite a few subjects here, including many new and unique concepts. 我在这里涉及了很多主题,包括许多新的和独特的概念。If you're new to T-SQL, you might feel overwhelmed at this point. 如果您是T-SQL的新手,此时您可能会感到不知所措。But remember, this chapter introduces some of the most important points about SQL that might be hard to digest at the beginning. 但请记住,本章介绍了一些最重要的SQL要点,这些要点在一开始可能很难理解。If some of the concepts weren't completely clear, you might want to revisit sections from this chapter later on, after you've had a chance to sleep on it.如果其中一些概念还不完全清楚,那么在你有机会细想之后,你可能会想在后面重温本章的章节。
For an opportunity to practice what you learned and absorb the material better, I recommend going over the chapter exercises.为了有机会练习你所学的内容,更好地吸收材料,我建议你复习本章的练习。
This section provides exercises to help you familiarize yourself with the subjects discussed in Chapter 2. 本节提供练习,帮助您熟悉第2章中讨论的主题。Solutions to the exercises appear in the section that follows.练习的解决方案将出现在下面的部分中。
You can find instructions for downloading and installing the 您可以在附录中找到下载和安装TSQLV4 sample database in the Appendix.TSQLV4范例数据库的说明。
Write a query against the 针对Sales.Orders table that returns orders placed in June 2015:Sales.Orders表编写一个查询,该表返回2015年6月的订单:
Tables involved: 涉及的表:TSQLV4 database and the Sales.Orders tableTSQLV4数据库和Sales.Orders表
Desired output (abbreviated):期望输出(缩写):
orderid orderdate custid empid
----------- ---------- ----------- -----------
10555 2015-06-02 71 6
10556 2015-06-03 73 2
10557 2015-06-03 44 9
10558 2015-06-04 4 1
10559 2015-06-05 7 6
10560 2015-06-06 25 8
10561 2015-06-06 24 2
10562 2015-06-09 66 1
10563 2015-06-10 67 2
10564 2015-06-10 65 4
...
(30 row(s) affected)
Write a query against the 针对Sales.Orders table that returns orders placed on the last day of the month:Sales.Orders表编写一个查询,该表返回当月最后一天的订单:
Tables involved: 涉及的表:TSQLV4 database and the Sales.Orders tableTSQLV4数据库和Sales.Orders表
Desired output (abbreviated):期望输出(缩写):
orderid orderdate custid empid
----------- ---------- ----------- -----------
10269 2014-07-31 89 5
10317 2014-09-30 48 6
10343 2014-10-31 44 4
10399 2014-12-31 83 8
10432 2015-01-31 75 3
10460 2015-02-28 24 8
10461 2015-02-28 46 1
10490 2015-03-31 35 7
10491 2015-03-31 28 8
10522 2015-04-30 44 4
...
(26 row(s) affected)
Write a query against the 针对HR.Employees table that returns employees with a last name containing the letter e twice or more:HR.Employees表编写一个查询,该表返回姓氏包含字母e两次或两次以上的员工:
Tables involved: 涉及的表:TSQLV4 database and the HR.Employees tableTSQLV4数据库和HR.Employees表
Desired output:期望输出:
empid firstname lastname
----------- ---------- --------------------
4 Yael Peled
5 Sven Mortensen
(2 row(s) affected)
Write a query against the 针对Sales.OrderDetails table that returns orders with a total value (quantity * unitprice) greater than 10,000, sorted by total value:Sales.OrderDetails表编写一个查询,该表返回总值(数量*单价)大于10000的订单,按总值排序:
Tables involved: 涉及的表:TSQLV4 database and the Sales.OrderDetails tableTSQLV4数据库和Sales.OrderDetails表
Desired output:期望输出:
orderid totalvalue
----------- ---------------------
10865 17250.00
11030 16321.90
10981 15810.00
10372 12281.20
10424 11493.20
10817 11490.70
10889 11380.00
10417 11283.20
10897 10835.24
10353 10741.60
10515 10588.50
10479 10495.60
10540 10191.70
10691 10164.80
(14 row(s) affected)
To check the validity of the data, write a query against the 要检查数据的有效性,请对HR.Employees table that returns employees with a last name that starts with a lowercase English letter in the range a through z. HR.Employees表编写一个查询,该表返回姓氏以a到z范围内的小写英文字母开头的员工。Remember that the collation of the sample database is case insensitive (请记住,示例数据库的排序规则不区分大小写(Latin1_General_CI_AS):Latin1_General_CI_AS):
Tables involved: 涉及的表:TSQLV4 database and the HR.Employees tableTSQLV4数据库和HR.Employees表
Desired output is an empty set:所需输出为空集:
empid lastname
----------- --------------------
(0 row(s) affected))
Explain the difference between the following two queries:解释以下两个查询之间的差异:
-- Query 1
SELECT empid, COUNT(*) AS numorders
FROM Sales.Orders
WHERE orderdate < '20160501'
GROUP BY empid;
-- Query 2
SELECT empid, COUNT(*) AS numorders
FROM Sales.Orders
GROUP BY empid
HAVING MAX(orderdate) < '20160501';
Tables involved: 涉及的表:TSQLV4 database and the Sales.Orders tableTSQLV4数据库和Sales.Orders表
Write a query against the 针对Sales.Orders table that returns the three shipped-to countries with the highest average freight in 2015:Sales.Orders表编写一个查询,返回2015年平均运费最高的三个国家:
Tables involved: 涉及的表:TSQLV4 database and the Sales.Orders tableTSQLV4数据库和Sales.Orders表
Desired output:期望输出:
shipcountry avgfreight
--------------- ---------------------
Austria 178.3642
Switzerland 117.1775
Sweden 105.16
(3 row(s) affected)
Write a query against the 针对Sales.Orders table that calculates row numbers for orders based on order date ordering (using the order ID as the tiebreaker) for each customer separately:Sales.Orders表编写一个查询,该表分别根据每个客户的订单日期订单(使用订单ID作为分界线)计算订单的行号:
Tables involved: 涉及的表:TSQLV4 database and the Sales.Orders tableTSQLV4数据库和Sales.Orders表
Desired output (abbreviated):期望输出(缩写):
custid orderdate orderid rownum
----------- ---------- ----------- --------------------
1 2015-08-25 10643 1
1 2015-10-03 10692 2
1 2015-10-13 10702 3
1 2016-01-15 10835 4
1 2016-03-16 10952 5
1 2016-04-09 11011 6
2 2014-09-18 10308 1
2 2015-08-08 10625 2
2 2015-11-28 10759 3
2 2016-03-04 10926 4
...
(830 row(s) affected)
Using the 使用HR.Employees table, write a SELECT statement that returns for each employee the gender based on the title of courtesy. HR.Employees表,写一个SELECT语句,根据礼貌的标题为每位员工返回性别。For 'Ms.' and 'Mrs.' return 'Female'; for 'Mr.' return 'Male'; and in all other cases (for example, 'Dr.') return 'Unknown':对于“Ms.”和“Mrs.”,返回“女性”;对于“Mr.”,返回“男性”;在所有其他情况下(例如,“Dr.”返回“Unknown”:
Tables involved: 涉及的表:TSQLV4 database and the HR.Employees tableTSQLV4数据库和HR.Employees表
Desired output:期望输出:
empid firstname lastname titleofcourtesy gender
----------- ---------- -------------------- ------------------------- -------
1 Sara Davis Ms. Female
2 Don Funk Dr. Unknown
3 Judy Lew Ms. Female
4 Yael Peled Mrs. Female
5 Sven Mortensen Mr. Male
6 Paul Suurs Mr. Male
7 Russell King Mr. Male
8 Maria Cameron Ms. Female
9 Patricia Doyle Ms. Female
(9 row(s) affected)
Write a query against the 针对Sales.Customers table that returns for each customer the customer ID and region. Sales.Customers表编写一个查询,为每个客户返回客户ID和地区。Sort the rows in the output by region, having 按区域对输出中的行进行排序,最后排序为NULLs sort last (after non-NULL values). NULL(在非NULL值之后)。Note that the default sort behavior for 请注意,T-SQL中NULLs in T-SQL is to sort first (before non-NULL values):NULL的默认排序行为是先排序(在非NULL值之前):
Tables involved: 涉及的表:TSQLV4 database and the Sales.Customers tableTSQLV4数据库和Sales.Customers表
Desired output (abbreviated):期望输出(缩写):
custid region
----------- ---------------
55 AK
10 BC
42 BC
45 CA
37 Co. Cork
33 DF
71 ID
38 Isle of Wight
46 Lara
78 MT
...
1 NULL
2 NULL
3 NULL
4 NULL
5 NULL
6 NULL
7 NULL
8 NULL
9 NULL
11 NULL
...
(91 row(s) affected)
This section provides the solutions to the exercises for this chapter, accompanied by explanations where needed.本节提供本章练习的解决方案,并在必要时进行解释。
You might have considered using the 您可能已经考虑在解决方案查询的YEAR and MONTH functions in the WHERE clause of your solution query, like this:WHERE子句中使用YEAR和MONTH函数,如下所示:
USE TSQLV4;
SELECT orderid, orderdate, custid, empid
FROM Sales.Orders
WHERE YEAR(orderdate) = 2015 AND MONTH(orderdate) = 6;
This solution is valid and returns the correct result. 此解决方案有效,并返回正确的结果。However, I explained that if you apply manipulation to the filtered column, in most cases SQL Server can't use an index efficiently. 然而,我解释说,如果对筛选列应用操作,在大多数情况下SQL Server无法有效地使用索引。Therefore, I advise using a range filter instead:因此,我建议改用范围筛选器:
SELECT orderid, orderdate, custid, empid
FROM Sales.Orders
WHERE orderdate >= '20150601'
AND orderdate < '20150701';
You can use the 您可以使用EOMONTH function to address this task, like this:EOMONTH函数来处理此任务,如下所示:
SELECT orderid, orderdate, custid, empid
FROM Sales.Orders
WHERE orderdate = EOMONTH(orderdate);
I also provided an alternative expression for computing the last day of the month that corresponds to the input date value:我还提供了另一个表达式,用于计算与输入日期值相对应的月份最后一天:
DATEADD(month, DATEDIFF(month, '18991231', date_val), '18991231')
It is a more complex technique, but it has the advantage that you can use it to compute the beginning or end of other parts (day, month, quarter, year).这是一种更复杂的技术,但它的优点是,您可以使用它来计算其他部分(日、月、季度、年)的开始或结束。
This expression first calculates the difference in terms of whole months between an anchor last day of some month (December 31, 1899, in this case) and the specified date. 此表达式首先计算某个月的最后一天(本例中为1899年12月31日)与指定日期之间的整月差。Call this difference 称之为差异。diff. By adding 通过向锚定日期添加diff months to the anchor date, you get the last day of the target month. diff months,可以得到目标月的最后一天。Here's the full solution query, returning only orders that were placed on the last day of the month:以下是完整的解决方案查询,只返回当月最后一天下的订单:
SELECT orderid, orderdate, custid, empid
FROM Sales.Orders
WHERE orderdate = DATEADD(month, DATEDIFF(month, '18991231', orderdate), '18991231');
This exercise involves using pattern matching with the 本练习涉及使用LIKE predicate. LIKE谓词的模式匹配。Remember that the percent sign (请记住,百分号(%) represents a character string of any size, including an empty string. %)表示任意大小的字符串,包括空字符串。Therefore, you can use the pattern 因此,您可以使用模式'%e%e%' to express at least two occurrences of the character e anywhere in the string. '%e%e%'来表示字符串中至少两次出现的字符e。Here's the full solution query:以下是完整的解决方案查询:
SELECT empid, firstname, lastname
FROM HR.Employees
WHERE lastname LIKE '%e%e%';
This exercise is quite tricky, and if you managed to solve it correctly, you should be proud of yourself. 这个练习相当棘手,如果你成功地解决了它,你应该为自己感到自豪。A subtle requirement in the request might be overlooked or interpreted incorrectly. 请求中的细微要求可能会被忽略或错误解释。Observe that the request said “return orders with 请注意,请求中说的是“返回总价值大于10000的订单”,而不是“返回total value greater than 10,000” and not “return orders with value greater than 10,000.” value大于10000的订单”In other words, it's not the individual order detail row that is supposed to meet the requirement. 换句话说,应该满足要求的不是单个订单明细行。Instead, the group of all order details within the order should meet the requirement. 相反,订单中所有订单细节的组应该满足要求。This means that the query shouldn't have a filter in the 这意味着查询不应该在WHERE clause like this:WHERE子句中包含这样的筛选器:
WHERE quantity * unitprice > 10000
Rather, the query should group the data by the 相反,查询应该按照orderid attribute and have a filter in the HAVING clause like this:orderid属性对数据进行分组,并在HAVING子句中设置如下筛选器:
HAVING SUM(quantity*unitprice) > 10000
Here's the complete solution query:以下是完整的解决方案查询:
SELECT orderid, SUM(qty*unitprice) AS totalvalue
FROM Sales.OrderDetails
GROUP BY orderid
HAVING SUM(qty*unitprice) > 10000
ORDER BY totalvalue DESC;
You might have tried addressing the task using a query such as the following:您可能已尝试使用以下查询来解决该任务:
SELECT empid, lastname
FROM HR.Employees
WHERE lastname COLLATE Latin1_General_CS_AS LIKE N'[a-z]%';
The expression in the WHERE clause uses the COLLATE clause to convert the current case-insensitive collation of the lastname column to a case-sensitive one. WHERE子句中的表达式使用COLLATE子句将lastname列的当前不区分大小写的排序规则转换为区分大小写的排序规则。The LIKE predicate then checks that the case-sensitive last name starts with a letter in the range a through z. LIKE谓词然后检查区分大小写的姓氏是否以a到z范围内的字母开头。The tricky part here is that the specified collation uses dictionary sort order, in which the lowercase and uppercase forms of each letter appear next to each other and not in separate groups. 这里比较棘手的部分是,指定的排序规则使用字典排序顺序,每个字母的小写和大写形式彼此相邻,而不是单独分组。The sort order looks like this:排序顺序如下所示:
a
A
b
B
c
C
...
x
X
y
Y
z
Z
You realize that all the lowercase letters a through z, as well as the uppercase letters A through Y (excluding Z), qualify. 您知道所有小写字母a到z,以及大写字母A到Y(不包括Z)都符合条件。Therefore, if you run the preceding query, you get the following output:因此,如果运行前面的查询,将得到以下输出:
empid lastname
----------- --------------------
8 Cameron
1 Davis
9 Doyle
2 Funk
7 King
3 Lew
5 Mortensen
4 Peled
6 Suurs
To look only for the lowercase letters a through z, one solution is to list them explicitly in the LIKE pattern like this:为了只查找小写字母a到z,一种解决方案是以LIKE的模式显式列出它们:
SELECT empid, lastname
FROM HR.Employees
WHERE lastname COLLATE Latin1_General_CS_AS LIKE N'[abcdefghijklmnopqrstuvwxyz]%';
Naturally, there are other possible solutions.当然,还有其他可能的解决方案。
I'd like to thank Paul White who enlightened me when I fell into this trap myself in the past.我要感谢保罗·怀特,他在我过去落入这个陷阱时启发了我。
The WHERE clause is a row filter, whereas the HAVING clause is a group filter. WHERE子句是行筛选器,而HAVING子句是组筛选器。Query 1 filters only orders placed before May 2016, groups them by the employee ID, and returns the number of orders each employee handled among the filtered ones. 查询1只筛选2016年5月之前下的订单,按员工ID对其进行分组,并返回筛选的订单中每位员工处理的订单数。In other words, it computes how many orders each employee handled prior to May 2016. 换句话说,它计算出在2016年5月之前每位员工处理的订单数量。The query doesn't include orders placed in May 2016 or later in the count. 该查询不包括2016年5月或之后的订单。An employee will show up in the output as long as he or she handled orders prior to May 2016, regardless of whether the employee handled orders since May 2016. 只要员工在2016年5月之前处理过订单,无论该员工是否在2016年5月之后处理过订单,都会出现在输出中。Here's the output of Query 1:以下是查询1的输出:
empid numorders
----------- -----------
9 43
3 127
6 67
7 70
1 118
4 154
5 42
2 94
8 101
Query 2 groups all orders by the employee ID, and then filters only groups having a maximum date of activity prior to May 2016. 查询2根据员工ID对所有订单进行分组,然后只筛选活动最长日期在2016年5月之前的组。Then it computes the order count in each employee group. 然后计算每个员工组中的订单数量。The query discards the entire employee group if the employee handled any orders since May 2016. 如果员工自2016年5月以来处理过任何订单,则查询将丢弃整个员工组。In a sentence, this query returns for employees who didn't handle any orders since May 2016 the total number of orders they handled. 在一句话中,此查询返回自2016年5月以来未处理任何订单的员工所处理的订单总数。This query generates the following output:此查询生成以下输出:
empid numorders
----------- -----------
9 43
3 127
6 67
5 42
Take employee 1 as an example. 以员工1为例。This employee had activity both before and since May 2016. 该员工在2016年5月之前和之后都有活动。The first query result includes this employee, but the order count reflects only the orders the employee handled prior to May 2016. 第一个查询结果包括该员工,但订单数量仅反映该员工在2016年5月之前处理的订单。The second query result doesn't include this employee at all.第二个查询结果根本不包括该员工。
Because the request involves activity in the year 2015, the query should have a 因为请求涉及2015年的活动,所以查询应该有一个WHERE clause with the appropriate date-range filter (orderdate >= '20150101' AND orderdate < '20160101'). WHERE子句,带有适当的日期范围筛选器(orderdate >= '20150101' AND orderdate < '20160101')。Because the request involves average freight values per shipping country and the table can have multiple rows per country, the query should group the rows by country and calculate the average freight. 因为请求涉及每个装运国家的平均运费值,并且表中每个国家可以有多行,所以查询应该按国家对行进行分组,并计算平均运费。To get the three countries with the highest average freights, the query should specify 要获得平均运费最高的三个国家,查询应根据平均运费降序指定TOP (3), based on the order of average freight descending. TOP(3)。Here's the complete solution query:以下是完整的解决方案查询:
SELECT TOP (3) shipcountry, AVG(freight) AS avgfreight
FROM Sales.Orders
WHERE orderdate >= '20150101' AND orderdate < '20160101'
GROUP BY shipcountry
ORDER BY avgfreight DESC;
Remember that you can use the standard 请记住,您可以使用标准的OFFSET-FETCH filter instead of the proprietary TOP filter. OFFSET-FETCH筛选器,而不是专有的TOP筛选器。Here's the revised solution using 以下是使用OFFSET-FETCH:OFFSET-FETCH的修订解决方案:
SELECT shipcountry, AVG(freight) AS avgfreight
FROM Sales.Orders
WHERE orderdate >= '20150101' AND orderdate < '20160101'
GROUP BY shipcountry
ORDER BY avgfreight DESC
OFFSET 0 ROWS FETCH NEXT 3 ROWS ONLY;
Because the exercise requests that the row number calculation be done for each customer separately, the expression should partition the window by 因为该练习要求分别为每个客户进行行号计算,所以表达式应该按custid (PARTITION BY custid). custid对窗口进行分区(PARTITION BY custid)。In addition, the request was to use ordering based on the 此外,请求使用基于orderdate column, with the orderid column as a tiebreaker (ORDER BY orderdate, orderid). orderdate列的排序,orderid列作为分阶段符(ORDER BY orderdate, orderid)。Here's the complete solution query:以下是完整的解决方案查询:
SELECT custid, orderdate, orderid,
ROW_NUMBER() OVER(PARTITION BY custid ORDER BY orderdate, orderid) AS rownum
FROM Sales.Orders
ORDER BY custid, rownum;
You can handle the conditional logic in this exercise with a 您可以使用CASE expression. CASE表达式处理本练习中的条件逻辑。Using the simple 使用简单的CASE expression form, you specify the titleofcourtesy attribute right after the CASE keyword; list each possible title of courtesy in a separate WHEN clause followed by the THEN clause and the gender; and in the ELSE clause, specify 'Unknown'.CASE表达式表单,可以在CASE关键字后面指定titleOfcouresy属性;在单独的WHEN子句中列出每个可能的礼貌标题,后跟THEN子句和性别;在ELSE子句中,指定'Unknown'。
SELECT empid, firstname, lastname, titleofcourtesy,
CASE titleofcourtesy
WHEN 'Ms.' THEN 'Female'
WHEN 'Mrs.' THEN 'Female'
WHEN 'Mr.' THEN 'Male'
ELSE 'Unknown'
END AS gender
FROM HR.Employees;
You can also use the searched 您还可以使用带有两个谓词的搜索CASE form with two predicates—one to handle all cases where the gender is female and one for all cases where the gender is male—and an ELSE clause with 'Unknown'.CASE表单,一个用于处理性别为女性的所有情况,一个用于处理性别为男性的所有情况,另一个用于带有'Unknown'的ELSE子句。
SELECT empid, firstname, lastname, titleofcourtesy,
CASE
WHEN titleofcourtesy IN('Ms.', 'Mrs.') THEN 'Female'
WHEN titleofcourtesy = 'Mr.' THEN 'Male'
ELSE 'Unknown'
END AS gender
FROM HR.Employees;
By default, SQL Server sorts 默认情况下,SQL Server会在非NULLs before non-NULL values. NULL值之前对NULL进行排序。To get 为了让NULLs to sort last, you can use a CASE expression that returns 1 when the region column is NULL and 0 when it is not NULL. NULL最后排序,可以使用一个CASE表达式,当region列为NULL时返回1,当它不为NULL时返回0。Specify this 将此CASE expression as the first sort column and the region column as the second. CASE表达式指定为第一个排序列,将region列指定为第二个排序列。This way, non-这样一来,非空值会在它们之间正确排序,首先是NULLs sort correctly among themselves first followed by NULLs. NULL值,然后是非NULL值。Here's the complete solution query:以下是完整的解决方案查询:
SELECT custid, region
FROM Sales.Customers
ORDER BY
CASE WHEN region IS NULL THEN 1 ELSE 0 END, region;