GridFS¶
On this page
Overview概述¶
In this guide, you can learn how to store and retrieve large files in MongoDB using GridFS. 在本指南中,您可以学习如何使用GridFS在MongoDB中存储和检索大型文件。GridFS is a specification that describes how to split files into chunks during storage and reassemble them during retrieval. GridFS是一个规范,它描述了如何在存储期间将文件分割成块,并在检索期间重新组装它们。The driver implementation of GridFS manages the operations and organization of the file storage.GridFS的驱动程序实现管理文件存储的操作和组织。
You should use GridFS if the size of your file exceeds the BSON-document size limit of 16 megabytes. 如果文件大小超过BSON文档大小16 MB的限制,则应使用GridFS。For more detailed information on whether GridFS is suitable for your use case, see the GridFS server manual page.有关GridFS是否适合您的用例的更多详细信息,请参阅GridFS服务器手册页面。
Navigate the following sections to learn more about GridFS operations and implementation:浏览以下部分以了解有关GridFS操作和实现的更多信息:
How GridFS WorksGridFS的工作原理¶
GridFS organizes files in a bucket, a group of MongoDB collections that contain the chunks of files and descriptive information. GridFS将文件组织在一个bucket中,bucket是一组MongoDB集合,其中包含文件块和描述性信息。Buckets contain the following collections, named using the convention defined in the GridFS specification:Bucket包含以下集合,使用GridFS规范中定义的约定命名:
Thechunkscollection stores the binary file chunks.chunks集合存储二进制文件块。Thefilescollection stores the file metadata.files集合存储文件元数据。
When you create a new GridFS bucket, the driver creates the 创建新的GridFS存储桶时,驱动程序将创建chunks and files collections, prefixed with the default bucket name fs, unless you specify a different name. chunks和files集合,前缀为默认存储桶名称fs,除非指定其他名称。The driver also creates an index on each collection to ensure efficient retrieval of files and related metadata. 驱动程序还为每个集合创建索引,以确保高效检索文件和相关元数据。The driver only creates the GridFS bucket on the first write operation if it does not already exist. 驱动程序仅在第一次写入操作时创建GridFS bucket(如果它不存在)。The driver only creates indexes if they do not exist and when the bucket is empty. 驱动程序仅在索引不存在且存储桶为空时创建索引。For more information on GridFS indexes, see the server manual page on GridFS Indexes.有关GridFS索引的更多信息,请参阅关于GridFS索引的服务器手册页面。
When storing files with GridFS, the driver splits the files into smaller pieces, each represented by a separate document in the 当使用GridFS存储文件时,驱动程序会将文件分割成更小的片段,每个片段由chunks collection. chunks集合中的单独文档表示。It also creates a document in the 它还会在files collection that contains a unique file id, file name, and other file metadata. files集合中创建一个文档,其中包含唯一的文件id、文件名和其他文件元数据。You can upload the file from memory or from a stream. 您可以从内存或流上载文件。The following diagram describes how GridFS splits files when uploading to a bucket:下图描述了GridFS在上载到bucket时如何拆分文件:
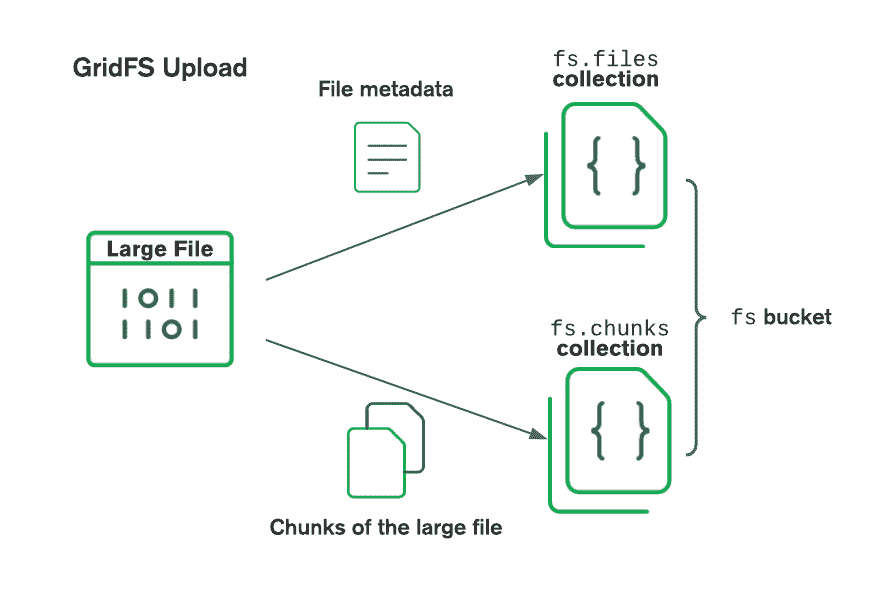
When retrieving files, GridFS fetches the metadata from the 检索文件时,GridFS从指定bucket中的files collection in the specified bucket and uses the information to reconstruct the file from documents in the chunks collection. files集合获取元数据,并使用该信息从chunks集合中的文档重建文件。You can read the file into memory or output it to a stream.您可以将文件读入内存或输出到流中。
Create a GridFS Bucket创建一个GridFS存储桶¶
Create a bucket or get a reference to an existing one to begin storing or retrieving files from GridFS. 创建一个bucket或获取对现有bucket的引用,以开始从GridFS存储或检索文件。Create a 创建一个GridFSBucket instance, passing a database as the parameter. GridFSBucket实例,将数据库作为参数传递。You can then use the 然后,您可以使用GridFSBucket instance to call read and write operations on the files in your bucket:GridFSBucket实例调用对bucket中文件的读写操作:
const db = client.db(dbName);
const bucket = new mongodb.GridFSBucket(db);Pass your bucket name as the second parameter to the 将bucket name作为第二个参数传递给create() method to create or reference a bucket with a custom name other than the default name fs, as shown in the following example:create()方法,以创建或引用具有自定义名称而不是默认名称fs的bucket,如下例所示:
const bucket = new mongodb.GridFSBucket(db, { bucketName: 'myCustomBucket' });For more information, see the GridFSBucket API documentation.有关更多信息,请参阅GridFSBucket API文档。
Upload Files上传文件¶
Use the 使用openUploadStream() method from GridFSBucket to create an upload stream for a given file name. GridFSBucket中的openUploadStream()方法为给定文件名创建上载流。You can use the 可以使用pipe() method to connect a Node.js fs read stream to the upload stream. pipe()方法将Node.js fs读取流连接到上载流。The openUploadStream() method allows you to specify configuration information such as file chunk size and other field/value pairs to store as metadata. openUploadStream()方法允许您指定配置信息,如文件块大小和其他字段/值对,以存储为元数据。Set these options as parameters of 将这些选项设置为openUploadStream() as shown in the following code snippet:openUploadStream()的参数,如以下代码段所示:
fs.createReadStream('./myFile').
pipe(bucket.openUploadStream('myFile', {
chunkSizeBytes: 1048576,
metadata: { field: 'myField', value: 'myValue' }
});See the openUploadStream() API documentation for more information.有关更多信息,请参阅openUploadStream()API文档。
Retrieve File Information检索文件信息¶
In this section, you can learn how to retrieve file metadata stored in the 在本节中,您可以学习如何检索存储在GridFS bucket的files collection of the GridFS bucket. files集合中的文件元数据。The metadata contains information about the file it refers to, including:元数据包含有关其引用的文件的信息,包括:
The文件的_idof the file_idThe name of the file文件名The length/size of the file文件的长度/大小The upload date and time上载日期和时间A可以在其中存储任何其他信息的metadatadocument in which you can store any other informationmetadata文档
Call the 在find() method on the GridFSBucket instance to retrieve files from a GridFS bucket. GridFSBucket实例上调用find()方法,从GridFS bucket检索文件。The method returns a 该方法返回一个FindCursor实例,您可以从中访问结果。FindCursor instance from which you can access the results.
The following code example shows you how to retrieve and print file metadata from all your files in a GridFS bucket. 下面的代码示例演示如何从GridFS存储桶中的所有文件中检索和打印文件元数据。Among the different ways that you can traverse the retrieved results from the 在可以遍历FindCursor iterable, the following example uses the forEach() method to display the results:FindCursor iterable中检索到的结果的各种方法中,以下示例使用forEach()方法显示结果:
const cursor = bucket.find({});
cursor.forEach(doc=> console.log(doc));The find() method accepts various query specifications and can be combined with other methods such as sort(), limit(), and project().find()方法接受各种查询规范,并可以与其他方法(如sort()、limit()和project()组合使用。
For more information on the classes and methods mentioned in this section, see the following resources:有关本节中提到的类和方法的更多信息,请参阅以下参考资料:
Download Files下载文件¶
You can download files from your MongoDB database by using the 通过使用openDownloadStreamByName() method from GridFSBucket to create a download stream.GridFSBucket中的openDownloadStreamByName()方法创建下载流,可以从MongoDB数据库下载文件。
The following example shows you how to download a file referenced by the file name, stored in the 以下示例演示如何将存储在filename field, into your working directory:filename字段中的文件名引用的文件下载到工作目录中:
bucket.openDownloadStreamByName('myFile').
pipe(fs.createWriteStream('./outputFile'));If there are multiple documents with the same 如果有多个文档具有相同的filename value, GridFS will stream the most recent file with the given name (as determined by the uploadDate field).filename值,GridFS将以给定的名称(由uploadDate字段确定)流式传输最近的文件。
Alternatively, you can use the 或者,您可以使用openDownloadStream() method, which takes the _id field of a file as a parameter:openDownloadStream()方法,该方法将文件的_id字段作为参数:
bucket.openDownloadStream(ObjectId("60edece5e06275bf0463aaf3")).
pipe(fs.createWriteStream('./outputFile'));The GridFS streaming API cannot load partial chunks. When a download stream needs to pull a chunk from MongoDB, it pulls the entire chunk into memory. GridFS流API无法加载部分块。当下载流需要从MongoDB中提取块时,它会将整个块提取到内存中。The 255 kilobyte default chunk size is usually sufficient, but you can reduce the chunk size to reduce memory overhead.255k字节的默认块大小通常足够了,但您可以减小块大小以减少内存开销。
For more information on the 有关openDownloadStreamByName() method, see its API documentation.openDownloadStreamByName()方法的更多信息,请参阅其API文档。
Rename Files文件重命名¶
Use the 使用rename() method to update the name of a GridFS file in your bucket. rename()方法更新bucket中GridFS文件的名称。You must specify the file to rename by its 必须按文件的_id field rather than its file name._id字段而不是文件名指定要重命名的文件。
The rename() method only supports updating the name of one file at a time. rename()方法一次只支持更新一个文件的名称。To rename multiple files, retrieve a list of files matching the file name from the bucket, extract the 要重命名多个文件,请从bucket中检索与文件名匹配的文件列表,从要重命名的文件中提取_id field from the files you want to rename, and pass each value in separate calls to the rename() method._id字段,并在单独的调用中将每个值传递给rename()方法。
The following example shows how to update the 以下示例显示了如何通过引用文档的filename field to "newFileName" by referencing a document's _id field:_id字段将filename字段更新为“newFileName”:
bucket.rename(ObjectId("60edece5e06275bf0463aaf3"), "newFileName");For more information on this method, see the rename() API documentation.有关此方法的更多信息,请参阅rename()API文档。
Delete Files删除文件¶
Use the 使用delete() method to remove a file from your bucket. delete()方法从bucket中删除文件。You must specify the file by its 必须通过文件的_id field rather than its file name._id字段而不是文件名来指定文件。
The delete() method only supports deleting one file at a time. delete()方法一次只支持删除一个文件。To delete multiple files, retrieve the files from the bucket, extract the 要删除多个文件,请从bucket中检索文件,从要删除的文件中提取_id field from the files you want to delete, and pass each value in separate calls to the delete() method._id字段,并分别调用delete()方法传递每个值。
The following example shows you how to delete a file by referencing its 以下示例显示如何通过引用文件的_id field:_id字段来删除文件:
bucket.delete(ObjectId("60edece5e06275bf0463aaf3"));For more information on this method, see the delete() API documentation.有关此方法的更多信息,请参阅delete()API文档。
Delete a GridFS Bucket删除GridFS存储桶¶
Use the 使用drop() method to remove a bucket's files and chunks collections, which effectively deletes the bucket. drop()方法删除bucket的files和chunks集合,这将有效地删除bucket。The following code example shows you how to delete a GridFS bucket:下面的代码示例演示如何删除GridFS存储桶:
bucket.drop();For more information on this method, see the drop() API documentation.有关此方法的更多信息,请参阅drop()API文档。
Additional Resources额外资源¶
- MongoDB GridFS specification
- Runnable example
from the Node driver version 3.6 documentation来自节点驱动程序版本3.6文档