
Spreadsheet Content Overview电子表格内容概述
A SpreadsheetML document is a package containing a number of different parts, mostly XML files.SpreadsheetML文档是一个包含许多不同部分的包,主要是XML文件。
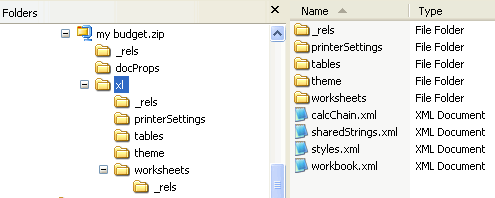
However, most of the actual content is found within one or more worksheet parts (one for each worksheet), and one sharedStrings part. 但是,大多数实际内容都存在于一个或多个工作表部分(每个工作表一个部分)和一个sharedStrings部分中。For Microsoft Excel, the content is found within an xl folder, and the worksheets are within a worksheet sub-folder.对于Microsoft Excel,内容位于xl文件夹中,工作表位于工作表子文件夹中。
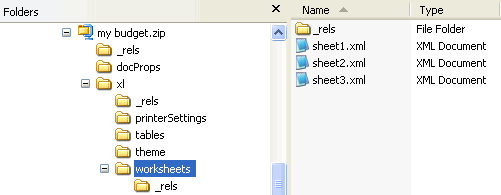
The workbook part contains no actual content but merely some properties of the spreadsheet, with references to the separate worksheet parts which contain the data.工作簿部分不包含实际内容,只包含电子表格的一些属性,并引用包含数据的单独工作表部分。
A worksheet can be either a grid, a chart, or a dialog sheet.工作表可以是网格、图表或对话框。
The Grid网格
A grid of cells (or a "cell table") is the most common type or worksheet. 单元格网格(或“单元格表”)是最常见的类型或工作表。Cells can contain text, booleans, numbers, dates, and formulas. 单元格可以包含文本、布尔值、数字、日期和公式。It is important to understand from the outset that most text values are not stored within a worksheept part. 从一开始就必须了解,大多数文本值并不存储在工作表零件中。In an effort to minimize duplication of values, a cell value that is a string is stored separately in the shareStrings part. 为了尽量减少值的重复,作为字符串的单元格值单独存储在shareStrings部分中。(There is an exception to this generalization, however. (然而,这一概括有一个例外。A cell can be of type inlineStr, in which case the string is stored in the cell itself, within an is element.) 单元格可以是inlineStr类型,在这种情况下,字符串存储在单元格本身的is元素中。)All other cell values--booleans, numbers, dates, and formulas (as well as the values of formulas) are stored within the cell.所有其他单元格值——布尔值、数字、日期和公式(以及公式的值)都存储在单元格中。
Some properties for the sheet are at the beginning of the root <worksheet> element. 图纸的某些属性位于根<worksheet>元素的开头。The number and sizes of the columns of the grid are defined within a <cols>. 网格列的数量和大小在<cols>中定义。And then the core data of the worksheet follows within the <sheetData> element. 然后工作表的核心数据在跟随其后的<sheetData>元素中。The sheet data is divided into rows (<row>), and within each row are cells (<c>). 图纸数据分为多行(<row>),每行中都有单元格(<c>)。Rows are numbered or indexed, beginning with 1, with the r attribute (e.g., row r="1"). 行被编号或索引,从1开始,带有r属性(例如,row r="1")。Each cell in the row also has a reference attribute which combines the row number with the column to make the reference attribute (e.g., <c r="D3">). 行中的每个单元格还具有一个引用属性,该属性将行号与列组合在一起以形成引用属性(例如,<c r="D3">)。If a cell within a row has no content, then the cell is omitted from the row definition.如果行中的单元格没有内容,则该单元格将从行定义中忽略。
The make-up of a cell is important in understanding the overall architecture of the spreadsheet content. 单元格的组成对于理解电子表格内容的总体架构非常重要。Each cell specifies its type with the t attribute. Possible values include:每个单元格都使用t属性指定其类型。可能的值包括:
- b
for boolean用于布尔值 - d
for date用于数据 - e
for error用于错误 - inlineStr
for an inline string (i.e., not stored in the shared strings part, but directly in the cell)用于内联字符串(即,不存储在共享字符串部分,而是直接存储在单元格中) - n
for number用于数字 - s
for shared string (so stored in the shared strings part and not in the cell)用于共享字符串(因此存储在共享字符串部分而不是单元格中) - str
for a formula (a string representing the formula)用于公式(表示公式的字符串)
When a cell is a number, then the value is stored in the <v> element as a child of <c> (the cell element).当单元格为数字时,该值存储在作为<c>(单元格元素)的子元素的<v>元素中。
A date is the same, though the date is stored as a value in the ISO 8601 format. 虽然日期以ISO 8601格式存储为值,但日期是相同的。For inline strings, the value is within an <is> element. 对于内联字符串,该值在<is>元素中。But of course the actual text is further nested within a t since the text can be formatted.但是,由于文本可以格式化,因此实际文本进一步嵌套在t中。
For a formula, the formula itself is stored within an f element as a child element of <c>. 对于公式,公式本身存储在作为<c>的子元素的f元素中。Following the formula is the actual calculated value within a <v> element.公式后面是实际计算值,放在<v>元素内。
When the data type of the cell is s for shared string, then the string is stored in the shared strings part. 当单元格的数据类型为s表示共享字符串时,该字符串存储在共享字符串部分中。However, the cell still contains a value within a <v> element, and that value is the index (zero-based) of the stored string in the shared strings part. 但是,单元格中仍包含一个值<v>元素,该值是共享字符串部分中存储字符串的索引(从零开始)。So, for example, in the example below, the actual string is the 9th occurrence of the <si> element within the shared strings part.例如,在下面的示例中,实际字符串是共享字符串部分中的<si>元素的第9次出现。
The shared string part may look like this:共享字符串部分可能如下所示:
Tables表格
Data on a worksheet can be organized into tables. 工作表上的数据可以组织成表格。Tables help provide structure and formatting to the data by having clearly labeled columns, rows, and data regions. 表通过清晰地标记列、行和数据区域,有助于为数据提供结构和格式。Rows and columns can be added easily, and filter and sort abilities are automatically added with the drop down arrows. 可以轻松添加行和列,并使用下拉箭头自动添加筛选和排序功能。
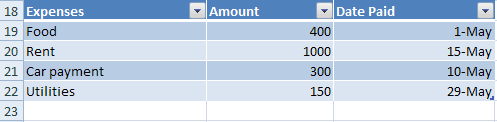
The actual table data for the cells is usually stored in the worksheet part as any other data, but the definition of the table is stored in a separate table part which is referenced from the worksheet in which the table appears.单元格的实际表格数据通常与任何其他数据一样存储在工作表部件中,但表格的定义存储在单独的表格部件中,该表格部件从表格所在的工作表中引用。
Within the rels part for the worksheet is the following:工作表的rels部分包括以下内容:
The table part is shown below.表格部分如下所示。
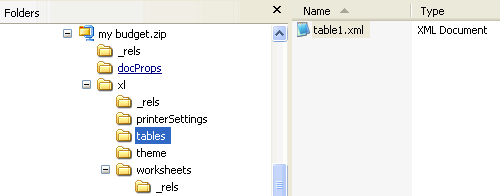
The content of the table part is below.下表部分的内容如下。
The ref attribute in red above defines the range of cells within the worksheet that comprise the table.上面红色的ref属性定义了工作表中组成表格的单元格范围。
Pivot Tables透视表
Pivot tables are used to aggregate data, and to summarize and display it in an understandable layout. 数据透视表用于聚合数据,并以可理解的布局汇总和显示数据。For example, suppose I have a large spreasheet which captures the sales of four products in four cities. 例如,假设我有一个大的spreasheet,它捕获了四个城市中四种产品的销售情况。I may have a column for the product, date, quantity sold, city, and state. 我可能有一个列的产品,日期,销售数量,城市和国家。Each day has an entry for each product in each city, or 16 entries per day. 每个城市的每种产品每天都有一个条目,或每天16个条目。So even with only 4 products in 4 cities, I could have 5840 rows of data for a year. What if wanted to determine what city had the most sales in the spring months? 因此,即使只有4个城市的4种产品,我一年也可以有5840行数据。如果我们想确定哪个城市在春季销售最多呢?What product was improving? 什么产品在改进?What city had the greatest sales of red widgets? 哪个城市的红色小部件销量最大?Pivot tables help to summarize the data and quickly provide the answers to these questions. 数据透视表有助于汇总数据并快速提供这些问题的答案。
Pivot tables have a row axis, a column axis, a values area, and a report filter area. 数据透视表具有行轴、列轴、值区域和报告过滤器区域。Each table also has a field list from which users can select which fields to include in the pivot table. 每个表还有一个字段列表,用户可以从中选择要包含在透视表中的字段。Below is a pivot table that summarizes the sales and revenue by product.下面是按产品汇总销售和收入的数据透视表。

A pivot table is comprised of the following components.数据透视表由以下组件组成。
There is the underlying data that the pivot table summarizes.透视表汇总了一些底层数据。This data may be on the same worksheet as the pivot table, on a different worksheet, or it may be from an external source.此数据可能与透视表位于同一工作表上,也可能位于不同的工作表上,或者可能来自外部源。A cache or copy of that data is created in a part called the pivotCacheRecords part; a cache is needed when, e.g., the external data source is unavailable.在称为pivotCacheRecords部件的部件中创建该数据的缓存或副本;例如,当外部数据源不可用时,需要缓存。There is a pivotCacheDefinition part that defines each field in the pivot table and contains shared items, much like the sharedStrings part contains strings to remove redundancy in a worksheet.pivotCacheDefinition部分定义数据透视表中的每个字段并包含共享项,就像sharedStrings部分包含字符串以消除工作表中的冗余一样。The pivotTable part defines the layout of the pivot table itself, specifying what fields are on the row axix, the column axix, the report filter, and the values area.数据透视表部分定义数据透视表本身的布局,指定行axix、列axix、报表筛选器和值区域上的字段。
The workbook points to and owns the pivotCacheDefinition part. 工作簿指向并拥有pivotCacheDefinition部分。There is the reference in the workbook to the cache of data for the pivot table, following the references to the worksheets:工作簿中有对数据透视表数据缓存的引用,在对工作表的引用之后:
The rels part for the workbook contains that reference:工作簿的rels部分包含该引用:
The pivotCacheDefinition part in turn points to the pivotCacheRecords part. pivotCacheDefinition部分依次指向pivotCacheRecords部分。
The pivotCacheDefinition part also references the source data in its <cacheSource> element: pivotCacheDefinition部分还引用了其<cacheSource>元素:
The worksheet that contains the pivot table references the pivotTable part. 包含数据透视表的工作表引用数据透视表零件。(There may be more than one, since a worksheet can have more than one pivot table.) (可能有多个数据透视表,因为一个工作表可以有多个数据透视表。)The rels part for the worksheet contains that reference:工作表的rels部分包含该引用:
The pivotTable part references the pivotCacheDefinitions part. 数据透视表零件参照数据透视表零件。The rels part for the pivotTable part contains that reference:数据透视表部件的rels部件包含该引用:
pivotCacheDefinition
Now let's look briefly at these parts and try to make sense out of them. 现在,让我们简要地看一下这些部分,并尝试从中理解它们。Let's begin with the pivotCacheDefinition. 让我们从pivotCacheDefinition开始。As mentioned above, it specifies the location of the source data. 如上所述,它指定源数据的位置。It also defines each field (such as data type and formatting to be used) in the source data, including those not used in the pivot table. 它还定义源数据中的每个字段(例如要使用的数据类型和格式),包括透视表中未使用的字段。(What fields are actually used is specified in the pivot table part.) (实际使用的字段在透视表部分中指定。)And it is used as a cache for shared strings, just as the SharedStrings part is used to store strings that appear in worksheets.它用作共享字符串的缓存,就像SharedStrings部分用于存储工作表中出现的字符串一样。
The definition of the six fields in our example worksheet is below. 下面是我们示例工作表中六个字段的定义。
The first field defined above is the product field. 上面定义的第一个字段是product字段。It consists of shared string values. 它由共享字符串值组成。If the field does not have shared string values (such as the second field defined above--the Quantity Sold field), then the values are stored directly in the pivotCacheRecords part. 如果该字段没有共享字符串值(如上面定义的第二个字段--“售出数量”字段),则这些值直接存储在pivotCacheRecords部分中。
pivotCacheRecords
Let's look at the pivotCacheRecords part to see how the field definitions relate to the cached data. 让我们看看pivotCacheRecords部分,看看字段定义与缓存数据的关系。Below are the first two rows of data in the cache.下面是缓存中的前两行数据。
This corresponds to the data from the worksheet shown below.这与下面显示的工作表中的数据相对应。

Note first that each record (<r>) of the cached data has the same number of values as are defined in the pivotCacheDefinition--in our case, six. 首先请注意,缓存数据的每条记录(<r>)的值数与pivotCacheDefinition中定义的值数相同——在本例中为六个。Within each record are the following possible elements:每个记录中都包含以下可能的元素:
- <x> -
indicating the index value referencing an item for the field as defined in the pivotCacheDefinition指示引用pivotCacheDefinition中定义的字段项的索引值 - <s> -
indicating a string value is being expressed inline in the record指示字符串值正在记录中内联表示 - <n> -
indicating a numeric value is being expressed inline in the record指示在记录中内联表示数值
Looking at the two sample records from the pivotCacheRecords above, we know from the pivotCacheDefinition that the six values are product, quantity, date, revenue, city, and state in that order. 查看上述pivotCacheRecords中的两个示例记录,我们从pivotCacheDefinition中知道这六个值依次为产品、数量、日期、收入、城市和州。The Product field in the first record is <x v="0"/>, so the value (0) is an index into the items listed in the product field. 第一条记录中的产品字段为<x v="0"/>,因此,值(0)是product字段中列出的项目的索引。The first one listed (index 0) is Green Widget. 列出的第一个(索引0)是绿色小部件。The second or quantity field value is <n v="2"/>, so the value (2) is a numeric value expressed inline. 第二个或数量字段值为<n v="2"/>,因此,值(2)是一个内联表示的数值。The third or date field value is <x v="0"/>, so the value (0) is an index into the items listed in the date field (2012-03-04T00:00:00 or 3/4). 第三个或日期字段值为<x v="0"/>,因此,值(0)是日期字段(2012-03-04T00:00:00或3/4)中列出的项目的索引。Etc.等
pivotTable数据透视表
Now let's look at the pivotTable part. 现在让我们看一下数据透视表部分。The root element is the <pivotTableDefinition> element. 根元素是<pivotTableDefinition>元素。There are several components within this. 这里面有几个组件。First, the location of the pivot table on the worksheet is specified. 首先,指定数据透视表在工作表上的位置。The location is straightforward. Note that both the first header and data columns are specified.位置很简单。请注意,第一个标题和数据列都已指定。
The order of items for fields and other field information for each field is then specified by <pivotField> elements within a <pivotFields>.字段的项目顺序和每个字段的其他字段信息由<pivotFields>中的<pivotField>元素指定。
From the pivotCacheDefinition we know that the first <pivotField> above is the product. 根据pivotCacheDefinition,我们知道上面的第一个<pivotField>是产品。It has 5 items listed. 它列出了5个项目。The first one is <item sd="0" x="3"/>. 第一个是<item sd="0" x="3"/>。The sd attribute indicates whether the item is hidden. sd属性指示项目是否隐藏。A value of 0 means the item is not hidden. 值为0表示该项未隐藏。The x attribute is the index for the items in the <cacheField> for the product in the pivotCacheDefinition. x属性是针对pivotCacheDefinition中的产品<cacheField>项的索引。The <cacheField> is shown below. 这个<cacheField>如下所示。Note that the value of the item at index 3 is Blue Widget, so Blue Widget should appear first in the pivot table if and where the product field is shown. 请注意,索引3处的项的值是Blue Widget,因此,如果产品字段显示在透视表中,蓝色小部件应该首先出现在透视表中。
The second item has an index of 0, or "Green Widget", the third is 2 or "Grey Widget," and the fourth is 1 or "Red Widget." 第二项的索引为0或“绿色小部件”,第三项为2或“灰色小部件”,第四项为1或“红色小部件”。Note that <item t="default"/> indicates a subtotal or total.请注意<item t="default"/>指示小计或总计。
Following the <pivotFields> collection is the <rowFields> collection. 跟在<pivotFields>集合后面的是<rowFields>集合。This collection specifies what fields are actually in the pivot table on the row axis, and in what order. 此集合指定数据透视表中行轴上的实际字段以及字段的顺序。In our example, when we fully expand the first row, we see that a row consists of first a product, then a city, followed by a state, and then a date. 在我们的示例中,当我们完全展开第一行时,我们看到一行首先由一个产品组成,然后是一个城市,接着是一个州,然后是一个日期。These are the row fields.这些是行字段。
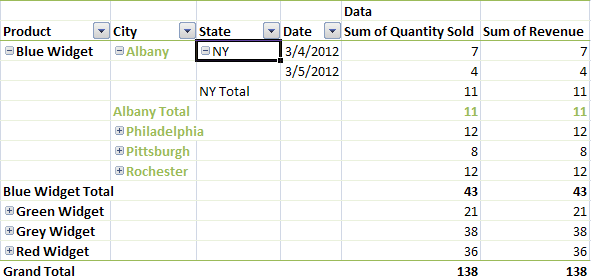
Following the index order in the <pivotFields> collection, this is 0, 4, 5, 2. 按照<pivotFields>集合中的索引顺序,这是0,4,5,2。The corresponding <rowFields> looks like this.相应的<rowFields>看起来像这样。
After the <rowFields> collection is the <rowItems> collection. <rowFields>集合之后是<rowItems>集合。This is a collection of all the values in the row axis. 这是行轴中所有值的集合。There is an <i> element for each row in the pivot table. 针对数据透视表中每一行有一个<i>元素。And for each <i> there are as many <x> elements as there are item values in the row. 对于每个<i>,<x>元素的数目等于行中的项目值。The v attribute is a zero-based index referencing a <pivotField> item value. v属性是基于零的索引,引用了一个<pivotField>项目值。If there is no v then the value is assumed to be 0. 如果没有v,则假定该值为0。The value of grand for t indicates a grand total as the last row item value.t的grand值表示作为最后一行项目值的总计。
The <colFields> collection follows, indicating which fields are on the column axis of the pivot table. 后面的<colFields>集合,指示哪些字段位于数据透视表的列轴上。Here again <x> is an index into the <pivotField> collection.此处,<x>依然是对应于<pivotField>集合中的项的索引。
The <colItems> collection follows, listing all of the values on the column axis.这个<colItems>集合,列出列轴上的所有值。
There may also be a <pageFields> collection which describes which fields are found in the report filter area. 也可能有<pageFields>集合,该集合描述在报表筛选区域中找到的字段。
Finally, there is a <dataFields> collection, which describes what fields are found in the values area of the pivot table. 最后,还有一个<dataFields>集合,它描述在数据透视表的值区域中可以找到哪些字段。In our example, there are two fields in the values area -- sum of quantity sold and sum of revenue. 在我们的示例中,values区域中有两个字段——销售数量总和和收入总和。Below is the collection. 以下是收藏。The fld attribute is the index of the field being summarized.fld属性是要汇总的字段的索引。