The Java Tutorials have been written for JDK 8.Java教程是为JDK 8编写的。Examples and practices described in this page don't take advantage of improvements introduced in later releases and might use technology no longer available.本页中描述的示例和实践没有利用后续版本中引入的改进,并且可能使用不再可用的技术。See Java Language Changes for a summary of updated language features in Java SE 9 and subsequent releases.有关Java SE 9及其后续版本中更新的语言特性的摘要,请参阅Java语言更改。
See JDK Release Notes for information about new features, enhancements, and removed or deprecated options for all JDK releases.有关所有JDK版本的新功能、增强功能以及已删除或不推荐的选项的信息,请参阅JDK发行说明。
Overview of the Sampled Package抽样包装概述
The javax.sound.sampled package is fundamentally concerned with audio transport — in other words, the Java Sound API focuses on playback and capture. javax.sound.sampled包从根本上与音频传输有关—换句话说,Java Sound API侧重于播放和捕获。The central task that the Java Sound API addresses is how to move bytes of formatted audio data into and out of the system. Java Sound API解决的中心任务是如何将格式化音频数据的字节移入和移出系统。This task involves opening audio input and output devices and managing buffers that get filled with real-time sound data. 这项任务包括打开音频输入和输出设备,管理填满实时声音数据的缓冲区。It can also involve mixing multiple streams of audio into one stream (whether for input or output). 它还包括将多个音频流混合到一个流中(无论是用于输入还是输出)。The transport of sound into or out of the system has to be correctly handled when the user requests that the flow of sound be started, paused, resumed, or stopped.当用户请求启动、暂停、恢复或停止声音流时,必须正确处理声音进出系统的传输。
To support this focus on basic audio input and output, the Java Sound API provides methods for converting between various audio data formats, and for reading and writing common types of sound files. 为了支持对基本音频输入和输出的关注,Java Sound API提供了各种音频数据格式之间的转换方法,以及读取和写入常见类型的声音文件的方法。However, it does not attempt to be a comprehensive sound-file toolkit. 然而,它并不试图成为一个全面的声音文件工具包。A particular implementation of the Java Sound API need not support an extensive set of file types or data format conversions. Java Sound API的特定实现不需要支持大量的文件类型或数据格式转换。Third-party service providers can supply modules that "plug in" to an existing implementation to support additional file types and conversions.第三方服务提供商可以提供“插件”到现有实现的模块,以支持其他文件类型和转换。
The Java Sound API can handle audio transport in both a streaming, buffered fashion and an in-memory, unbuffered fashion. Java Sound API可以以流式缓冲方式和内存中无缓冲方式处理音频传输。"Streaming" is used here in a general sense to refer to real-time handling of audio bytes; it does not refer to the specific, well-known case of sending audio over the Internet in a certain format. 这里的“流”一般指音频字节的实时处理;它并不是指通过互联网以某种格式发送音频的具体案例。In other words, a stream of audio is simply a continuous set of audio bytes that arrive more or less at the same rate that they are to be handled (played, recorded, etc.). 换句话说,音频流只是一组连续的音频字节,它们的到达速度与要处理(播放、录制等)的速度大致相同。Operations on the bytes commence before all the data has arrived. 字节操作在所有数据到达之前开始。In the streaming model, particularly in the case of audio input rather than audio output, you do not necessarily know in advance how long the sound is and when it will finish arriving. 在流媒体模型中,尤其是在音频输入而非音频输出的情况下,您不一定提前知道声音的长度以及到达时间。You simply handle one buffer of audio data at a time, until the operation is halted. 您只需一次处理一个音频数据缓冲区,直到操作停止。In the case of audio output (playback), you also need to buffer data if the sound you want to play is too large to fit in memory all at once. 在音频输出(播放)的情况下,如果要播放的声音太大,无法一次全部放入内存,则还需要缓冲数据。In other words, you deliver your audio bytes to the sound engine in chunks, and it takes care of playing each sample at the right time. 换句话说,你将音频字节分块发送到声音引擎,它负责在正确的时间播放每个样本。Mechanisms are provided that make it easy to know how much data to deliver in each chunk.提供了一些机制,可以很容易地知道每个数据块中要传递多少数据。
The Java Sound API also permits unbuffered transport in the case of playback only, assuming you already have all the audio data at hand and it is not too large to fit in memory. Java Sound API还允许仅在播放的情况下进行无缓冲传输,前提是您手头已经有了所有音频数据,并且数据不太大,无法放入内存。In this situation, there is no need for the application program to buffer the audio, although the buffered, real-time approach is still available if desired. 在这种情况下,应用程序不需要缓冲音频,但如果需要,缓冲实时方法仍然可用。Instead, the entire sound can be preloaded at once into memory for subsequent playback. 相反,整个声音可以一次预加载到内存中,以便后续播放。Because all the sound data is loaded in advance, playback can start immediately — for example, as soon as the user clicks a Start button. 因为所有声音数据都是预先加载的,所以可以立即开始播放—例如,只要用户单击开始按钮。This can be an advantage compared to the buffered model, where the playback has to wait for the first buffer to fill. 与缓冲模型相比,这可能是一个优势,在缓冲模型中,回放必须等待第一个缓冲区填满。In addition, the in-memory, unbuffered model allows sounds to be easily looped (cycled) or set to arbitrary positions in the data.此外,内存中的无缓冲模型允许声音轻松循环(循环)或设置到数据中的任意位置。
To play or capture sound using the Java Sound API, you need at least three things: formatted audio data, a mixer, and a line. The following provides an overview of these concepts.要使用Java sound API播放或捕获声音,至少需要三件事:格式化的音频数据、混音器和一条线路。下文概述了这些概念。
What is Formatted Audio Data?什么是格式化音频数据?
Formatted audio data refers to sound in any of a number of standard formats. 格式化音频数据指的是多种标准格式的声音。The Java Sound API distinguishes between data formats and file formats. Java Sound API区分数据格式和文件格式。
Data Formats数据格式
A data format tells you how to interpret a series of bytes of "raw" sampled audio data, such as samples that have already been read from a sound file, or samples that have been captured from the microphone input. 数据格式告诉您如何解释一系列字节的“原始”采样音频数据,例如已从声音文件读取的样本,或已从麦克风输入捕获的样本。You might need to know, for example, how many bits constitute one sample (the representation of the shortest instant of sound), and similarly you might need to know the sound's sample rate (how fast the samples are supposed to follow one another). 例如,您可能需要知道一个样本由多少个比特组成(代表声音的最短瞬间),同样,您可能需要知道声音的采样率(样本之间应该以多快的速度跟随)。When setting up for playback or capture, you specify the data format of the sound you are capturing or playing.设置播放或捕获时,请指定要捕获或播放的声音的数据格式。
In the Java Sound API, a data format is represented by an 在Java Sound API中,数据格式由AudioFormat object, which includes the following attributes:AudioFormat对象表示,该对象包括以下属性:
Encoding technique, usually pulse code modulation (PCM)编码技术,通常是脉冲编码调制(PCM)Number of channels (1 for mono, 2 for stereo, etc.)通道数(1个用于单声道,2个用于立体声等)Sample rate (number of samples per second, per channel)采样率(每秒每个通道的采样数)Number of bits per sample (per channel)每个采样的位数(每个通道)Frame rate帧速率Frame size in bytes帧大小(字节)Byte order (big-endian or little-endian)字节顺序(大端或小端)
PCM is one kind of encoding of the sound waveform. PCM是声音波形的一种编码。The Java Sound API includes two PCM encodings that use linear quantization of amplitude, and signed or unsigned integer values. Java Sound API包括两种PCM编码,它们使用振幅的线性量化,以及有符号或无符号整数值。Linear quantization means that the number stored in each sample is directly proportional (except for any distortion) to the original sound pressure at that instant—and similarly proportional to the displacement of a loudspeaker or eardrum that is vibrating with the sound at that instant. 线性量化意味着每个样本中存储的数字与该时刻的原始声压成正比(任何失真除外),与该时刻随声音振动的扬声器或耳膜的位移成类似比例。Compact discs, for example, use linear PCM-encoded sound. Mu-law encoding and a-law encoding are common nonlinear encodings that provide a more compressed version of the audio data; these encodings are typically used for telephony or recordings of speech. 例如,CD使用线性PCM编码声音。Mu-law编码和a-law编码是常见的非线性编码,可提供更压缩的音频数据;这些编码通常用于电话或语音录音。A nonlinear encoding maps the original sound's amplitude to the stored value using a nonlinear function, which can be designed to give more amplitude resolution to quiet sounds than to loud sounds.非线性编码使用非线性函数将原始声音的振幅映射到存储值,该函数可以设计为使安静声音的振幅分辨率高于响亮声音的振幅分辨率。
A frame contains the data for all channels at a particular time. 帧包含特定时间所有通道的数据。For PCM-encoded data, the frame is simply the set of simultaneous samples in all channels, for a given instant in time, without any additional information. 对于PCM编码的数据,帧只是所有通道中给定时刻的同时采样集,没有任何附加信息。In this case, the frame rate is equal to the sample rate, and the frame size in bytes is the number of channels multiplied by the sample size in bits, divided by the number of bits in a byte.在这种情况下,帧速率等于采样率,以字节为单位的帧大小是通道数乘以以位为单位的采样大小,再除以字节中的位数。
For other kinds of encodings, a frame might contain additional information besides the samples, and the frame rate might be completely different from the sample rate. 对于其他类型的编码,帧可能包含样本之外的附加信息,并且帧速率可能与样本率完全不同。For example, consider the MP3 (MPEG-1 Audio Layer 3) encoding, which is not explicitly mentioned in the current version of the Java Sound API, but which could be supported by an implementation of the Java Sound API or by a third-party service provider. 例如,考虑MP3(MPEG-1 Audio Layer 3)编码,当前版本的Java Sound API中没有明确提及该编码,但Java Sound API的实现或第三方服务提供商可以支持该编码。In MP3, each frame contains a bundle of compressed data for a series of samples, not just one sample per channel. 在MP3中,每个帧包含一系列样本的压缩数据包,而不是每个通道一个样本。Because each frame encapsulates a whole series of samples, the frame rate is slower than the sample rate. 因为每个帧封装了一系列的采样,所以帧速率比采样率慢。The frame also contains a header. 框架还包含一个标题。Despite the header, the frame size in bytes is less than the size in bytes of the equivalent number of PCM frames. 尽管有标头,以字节为单位的帧大小小于同等数量PCM帧的字节大小。(After all, the purpose of MP3 is to be more compact than PCM data.) (毕竟,MP3的目的是比PCM数据更紧凑。)For such an encoding, the sample rate and sample size refer to the PCM data that the encoded sound will eventually be converted into before being delivered to a digital-to-analog converter (DAC).对于这种编码,采样率和采样大小指的是PCM数据,经过编码的声音最终将被转换成PCM数据,然后再传送到数模转换器(DAC)。
File Formats
A file format specifies the structure of a sound file, including not only the format of the raw audio data in the file, but also other information that can be stored in the file. 文件格式指定声音文件的结构,不仅包括文件中原始音频数据的格式,还包括可以存储在文件中的其他信息。Sound files come in various standard varieties, such as WAVE (also known as WAV, and often associated with PCs), AIFF (often associated with Macintoshes), and AU (often associated with UNIX systems). 声音文件有各种标准类型,如WAVE(也称为WAV,通常与PC机相关)、AIFF(通常与Macintoshes相关)和AU(通常与UNIX系统相关)。The different types of sound file have different structures. 不同类型的声音文件有不同的结构。For example, they might have a different arrangement of data in the file's "header." 例如,它们在文件的“头”中可能有不同的数据排列A header contains descriptive information that typically precedes the file's actual audio samples, although some file formats allow successive "chunks" of descriptive and audio data. 头包含的描述性信息通常位于文件的实际音频样本之前,尽管有些文件格式允许连续的“块”描述性和音频数据。The header includes a specification of the data format that was used for storing the audio in the sound file. 标题包括用于在声音文件中存储音频的数据格式规范。Any of these types of sound file can contain various data formats (although usually there is only one data format within a given file), and the same data format can be used in files that have different file formats.这些类型的声音文件中的任何一种都可以包含不同的数据格式(尽管在给定的文件中通常只有一种数据格式),并且相同的数据格式可以在具有不同文件格式的文件中使用。
In the Java Sound API, a file format is represented by an 在Java Sound API中,文件格式由AudioFileFormat object, which contains:AudioFileFormat对象表示,该对象包含:
The file type (WAVE, AIFF, etc.)文件类型(WAVE、AIFF等)The file's length in bytes文件的长度(字节)The length, in frames, of the audio data contained in the file文件中包含的音频数据的长度(以帧为单位)An AudioFormat object that specifies the data format of the audio data contained in the fileAudioFormat对象,指定文件中包含的音频数据的数据格式
The AudioSystem class provides methods for reading and writing sounds in different file formats, and for converting between different data formats. Some of the methods let you access a file's contents through a kind of stream called an AudioInputStream . An AudioInputStream is a subclass of the InputStream class, which encapsulates a series of bytes that can be read sequentially. To its superclass, the AudioInputStream class adds knowledge of the bytes' audio data format (represented by an AudioFormat object). By reading a sound file as an 通过将声音文件作为AudioInputStream, you get immediate access to the samples, without having to worry about the sound file's structure (its header, chunks, etc.). AudioInputStream读取,您可以立即访问样本,而不必担心声音文件的结构(其头、块等)。A single method invocation gives you all the information you need about the data format and the file type.一次方法调用就可以提供有关数据格式和文件类型的所有信息。
What is a Mixer?
Many application programming interfaces (APIs) for sound make use of the notion of an audio device. 许多声音应用程序编程接口(API)都使用音频设备的概念。A device is often a software interface to a physical input/output device. 设备通常是物理输入/输出设备的软件接口。For example, a sound-input device might represent the input capabilities of a sound card, including a microphone input, a line-level analog input, and perhaps a digital audio input.例如,声音输入设备可能代表声卡的输入能力,包括麦克风输入、线级模拟输入,以及数字音频输入。
In the Java Sound API, devices are represented by Mixer objects. The purpose of a mixer is to handle one or more streams of audio input and one or more streams of audio output. In the typical case, it actually mixes together multiple incoming streams into one outgoing stream. A Mixer object can represent the sound-mixing capabilities of a physical device such as a sound card, which might need to mix the sound coming in to the computer from various inputs, or the sound coming from application programs and going to outputs.
Alternatively, a Mixer object can represent sound-mixing capabilities that are implemented entirely in software, without any inherent interface to physical devices.
In the Java Sound API, a component such as the microphone input on a sound card is not itself considered a device — that is, a mixer — but rather a port into or out of the mixer. A port typically provides a single stream of audio into or out of the mixer (although the stream can be multichannel, such as stereo). 端口通常向混音器提供或从混音器中输出单个音频流(尽管音频流可以是多声道的,如立体声)。The mixer might have several such ports. For example, a mixer representing a sound card's output capabilities might mix several streams of audio together, and then send the mixed signal to any or all of various output ports connected to the mixer. 混合器可能有几个这样的端口。例如,代表声卡输出功能的混音器可能会将多个音频流混合在一起,然后将混合信号发送到连接到混音器的任何或所有不同输出端口。These output ports could be (for example) a headphone jack, a built-in speaker, or a line-level output.这些输出端口可以是(例如)耳机插孔、内置扬声器或线路级输出。
To understand the notion of a mixer in the Java Sound API, it helps to visualize a physical mixing console, such as those used in live concerts and recording studios.要理解Java Sound API中混音器的概念,可以将物理混音控制台可视化,例如现场音乐会和录音室中使用的混音控制台。
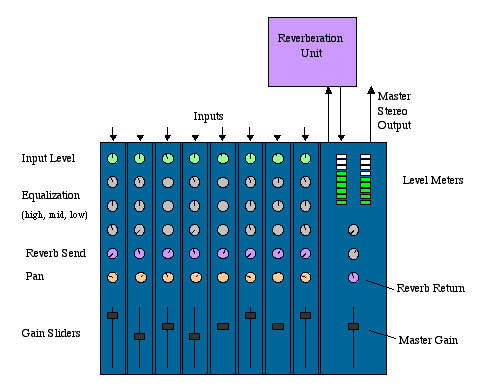
A Physical Mixing Console
A physical mixer has "strips" (also called "slices"), each representing a path through which a single audio signal goes into the mixer for processing. The strip has knobs and other controls by which you can control the volume and pan (placement in the stereo image) for the signal in that strip. Also, the mixer might have a separate bus for effects such as reverb, and this bus can be connected to an internal or external reverberation unit. Each strip has a potentiometer that controls how much of that strip's signal goes into the reverberated mix. The reverberated ("wet") mix is then mixed with the "dry" signals from the strips. A physical mixer sends this final mixture to an output bus, which typically goes to a tape recorder (or disk-based recording system) and/or speakers.
Imagine a live concert that is being recorded in stereo. 想象一下,一场现场音乐会正在用立体声录音。Cables (or wireless connections) coming from the many microphones and electric instruments on stage are plugged into the inputs of the mixing console. 来自舞台上许多麦克风和电子仪器的电缆(或无线连接)被插入混音控制台的输入端。Each input goes to a separate strip of the mixer, as illustrated. 如图所示,每个输入都会被传送到混合器的一个单独的条带。The sound engineer decides on the settings of the gain, pan, and reverb controls. 声音工程师决定增益、平移和混响控制的设置。The output of all the strips and the reverb unit are mixed together into two channels. 所有条带和混响单元的输出混合到两个通道中。These two channels go to two outputs on the mixer, into which cables are plugged that connect to the stereo tape recorder's inputs. 这两个通道连接到混音器的两个输出端,并将连接立体声录音机输入端的电缆插入其中。The two channels are perhaps also sent via an amplifier to speakers in the hall, depending on the type of music and the size of the hall.根据音乐的类型和大厅的大小,这两个频道也可能通过放大器发送到大厅中的扬声器。
Now imagine a recording studio, in which each instrument or singer is recorded to a separate track of a multitrack tape recorder. After the instruments and singers have all been recorded, the recording engineer performs a "mixdown" to combine all the taped tracks into a two-channel (stereo) recording that can be distributed on compact discs. In this case, the input to each of the mixer's strips is not a microphone, but one track of the multitrack recording. Once again, the engineer can use controls on the strips to decide each track's volume, pan, and reverb amount. The mixer's outputs go once again to a stereo recorder and to stereo speakers, as in the example of the live concert.
These two examples illustrate two different uses of a mixer: to capture multiple input channels, combine them into fewer tracks, and save the mixture, or to play back multiple tracks while mixing them down to fewer tracks.
In the Java Sound API, a mixer can similarly be used for input (capturing audio) or output (playing back audio). In the case of input, the source from which the mixer gets audio for mixing is one or more input ports. The mixer sends the captured and mixed audio streams to its target, which is an object with a buffer from which an application program can retrieve this mixed audio data. In the case of audio output, the situation is reversed. The mixer's source for audio is one or more objects containing buffers into which one or more application programs write their sound data; and the mixer's target is one or more output ports.
What is a Line?
The metaphor of a physical mixing console is also useful for understanding the Java Sound API's concept of a line.
A line is an element of the digital audio "pipeline" that is, a path for moving audio into or out of the system. Usually the line is a path into or out of a mixer (although technically the mixer itself is also a kind of line).
Audio input and output ports are lines. These are analogous to the microphones and speakers connected to a physical mixing console. Another kind of line is a data path through which an application program can get input audio from, or send output audio to, a mixer. These data paths are analogous to the tracks of the multitrack recorder connected to the physical mixing console.
One difference between lines in the Java Sound API and those of a physical mixer is that the audio data flowing through a line in the Java Sound API can be mono or multichannel (for example, stereo). By contrast, each of a physical mixer's inputs and outputs is typically a single channel of sound. To get two or more channels of output from the physical mixer, two or more physical outputs are normally used (at least in the case of analog sound; a digital output jack is often multichannel). In the Java Sound API, the number of channels in a line is specified by the AudioFormat of the data that is currently flowing through the line.
Let's now examine some specific kinds of lines and mixers. The following diagram shows different types of lines in a simple audio-output system that could be part of an implementation of the Java Sound API:
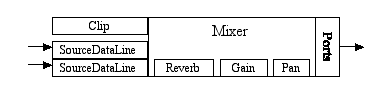
A Possible Configuration of Lines for Audio Output
In this example, an application program has gotten access to some available inputs of an audio-input mixer: one or more clips and source data lines. A clip is a mixer input (a kind of line) into which you can load audio data prior to playback; a source data line is a mixer input that accepts a real-time stream of audio data. The application program preloads audio data from a sound file into the clips. It then pushes other audio data into the source data lines, a buffer at a time. The mixer reads data from all these lines, each of which may have its own reverberation, gain, and pan controls, and mixes the dry audio signals with the wet (reverberated) mix. The mixer delivers its final output to one or more output ports, such as a speaker, a headphone jack, and a line-out jack.
Although the various lines are depicted as separate rectangles in the diagram, they are all "owned" by the mixer, and can be considered integral parts of the mixer. The reverb, gain, and pan rectangles represent processing controls (rather than lines) that can be applied by the mixer to data flowing through the lines.
Note that this is just one example of a possible mixer that is supported by the API. Not all audio configurations will have all the features illustrated. An individual source data line might not support panning, a mixer might not implement reverb, and so on.
A simple audio-input system might be similar:
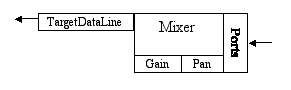
A Possible Configuration of Lines for Audio Input
Here, data flows into the mixer from one or more input ports, commonly the microphone or the line-in jack. Gain and pan are applied, and the mixer delivers the captured data to an application program via the mixer's target data line. A target data line is a mixer output, containing the mixture of the streamed input sounds. The simplest mixer has just one target data line, but some mixers can deliver captured data to multiple target data lines simultaneously.
The Line Interface Hierarchy
Now that we've seen some functional pictures of what lines and mixers are, let's discuss them from a slightly more programmatic perspective. Several types of line are defined by subinterfaces of the basic Line interface. The interface hierarchy is shown below.
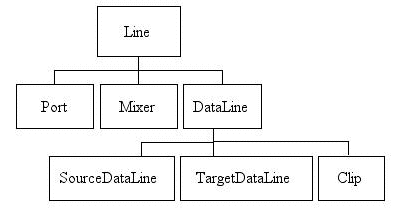
The Line Interface Hierarchy
The base interface, Line, describes the minimal functionality common to all lines:
- Controls – Data lines and ports often have a set of controls that affect the audio signal passing through the line. The Java Sound API specifies control classes that can be used to manipulate aspects of sound such as: gain (which affects the signal's volume in decibels), pan (which affects the sound's right-left positioning, reverb (which adds reverberation to the sound to emulate different kinds of room acoustics), and sample rate (which affects the rate of playback as well as the sound's pitch).
- Open or closed status – Successful opening of a line guarantees that resources have been allocated to the line. A mixer has a finite number of lines, so at some point multiple application programs (or the same one) might vie for usage of the mixer's lines. Closing a line indicates that any resources used by the line may now be released.
- Events – A line generates events when it opens or closes. Subinterfaces of
Linecan introduce other types of events. When a line generates an event, the event is sent to all objects that have registered to "listen" for events on that line. An application program can create these objects, register them to listen for line events, and react to the events as desired.
We'll now examine the subinterfaces of the Line interface.
Ports are simple lines for input or output of audio to or from audio devices. As mentioned earlier, some common types of ports are the microphone, line input, CD-ROM drive, speaker, headphone, and line output.
The Mixer interface represents a mixer, of course, which as we have seen represents either a hardware or a software device. The Mixer interface provides methods for obtaining a mixer's lines. These include source lines, which feed audio to the mixer, and target lines, to which the mixer delivers its mixed audio. For an audio-input mixer, the source lines are input ports such as the microphone input, and the target lines are TargetDataLines (described below), which deliver audio to the application program. For an audio-output mixer, on the other hand, the source lines are Clips or SourceDataLines (described below), to which the application program feeds audio data, and the target lines are output ports such as the speaker.
A Mixer is defined as having one or more source lines and one or more target lines. Note that this definition means that a mixer need not actually mix data; it might have only a single source line. The Mixer API is intended to encompass a variety of devices, but the typical case supports mixing.
The Mixer interface supports synchronization; that is, you can specify that two or more of a mixer's lines be treated as a synchronized group. Then you can start, stop, or close all those data lines by sending a single message to any line in the group, instead of having to control each line individually. With a mixer that supports this feature, you can obtain sample-accurate synchronization between lines.
The generic Line interface does not provide a means to start and stop playback or recording. For that you need a data line. The DataLine interface supplies the following additional media-related features beyond those of a Line:
- Audio format – Each data line has an audio format associated with its data stream.
- Media position – A data line can report its current position in the media, expressed in sample frames. This represents the number of sample frames captured by or rendered from the data line since it was opened.
- Buffer size – This is the size of the data line's internal buffer in bytes. For a source data line, the internal buffer is one to which data can be written, and for a target data line it's one from which data can be read.
- Level (the current amplitude of the audio signal)
- Start and stop playback or capture
- Pause and resume playback or capture
- Flush (discard unprocessed data from the queue)
- Drain (block until all unprocessed data has been drained from the queue, and the data line's buffer has become empty)
- Active status – A data line is considered active if it is engaged in active presentation or capture of audio data to or from a mixer.
- Events –
STARTandSTOPevents are produced when active presentation or capture of data from or to the data line starts or stops.
A TargetDataLine receives audio data from a mixer. Commonly, the mixer has captured audio data from a port such as a microphone; it might process or mix this captured audio before placing the data in the target data line's buffer. The TargetDataLine interface provides methods for reading the data from the target data line's buffer and for determining how much data is currently available for reading.
A SourceDataLine receives audio data for playback. It provides methods for writing data to the source data line's buffer for playback, and for determining how much data the line is prepared to receive without blocking.
A Clip is a data line into which audio data can be loaded prior to playback. Because the data is pre-loaded rather than streamed, the clip's duration is known before playback, and you can choose any starting position in the media. Clips can be looped, meaning that upon playback, all the data between two specified loop points will repeat a specified number of times, or indefinitely.
This section has introduced most of the important interfaces and classes of the sampled-audio API. Subsequent sections show how you can access and use these objects in your application program.